Neural Reflectance Decomposition
Extracting BRDF, shape, and illumination from images
Extracting BRDF, shape, and illumination from images
Mark Boss is a Ph.D. student working under the supervision of Prof. Hendrik P. A. Lensch in the Computer Graphics Group at the University of Tübingen. His research interests lie at the intersection of machine learning and computer graphics. The main research question is how to perform inverse rendering on sparse and casual captured images.
Student Researcher
June 2021 - April 2022
Research Intern
Nvidia
April 2019 - Juli 2019
Ph.D. Student
University of Tübingen
June 2018 - Juli 2022

[1] Result from: Boss et al. - NeRD: Neural Reflectance Decomposition from Image Collections - 2021

Boss et al. - SAMURAI: Shape And Material from Unconstrained Real-world Arbitrary Image collections - 2022
Boss et al. - SAMURAI: Shape And Material from Unconstrained Real-world Arbitrary Image collections - 2022
Boss et al. - SAMURAI: Shape And Material from Unconstrained Real-world Arbitrary Image collections - 2022
Boss et al. - SAMURAI: Shape And Material from Unconstrained Real-world Arbitrary Image collections - 2022
[1] James T. Kajiya - The Rendering Equation - 1986
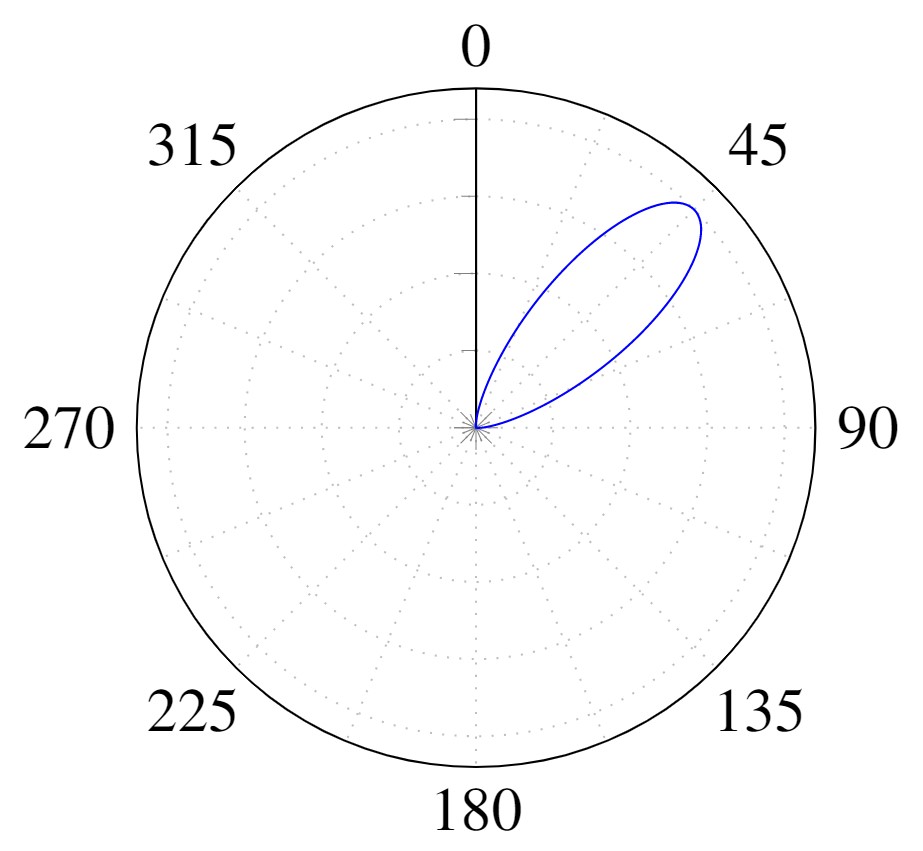
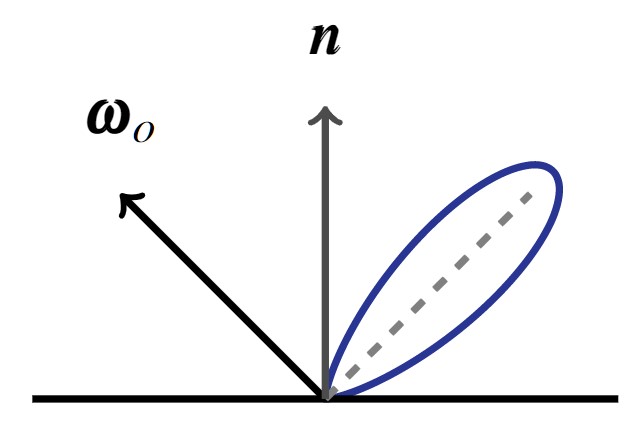
$$ \definecolor{out}{RGB}{219,135,217} \definecolor{emit}{RGB}{125,194,103} \definecolor{int}{RGB}{127,151,236} \definecolor{in}{RGB}{225,145,83} \definecolor{brdf}{RGB}{0,202,207} \definecolor{ndl}{RGB}{235,120,152} \definecolor{point}{RGB}{232,0,19} \color{out}L_{o}(\color{point}{\mathbf x}\color{out},\,\omega_{o})\color{black}\,= \fragment{1}{\,\color{emit}L_{e}({\mathbf x},\,\omega_{o})} \fragment{2}{\color{black} + \\ \color{int}\int_{\Omega }} \fragment{4}{\color{brdf}f_{r}({\mathbf x},\,\omega_{i},\,\omega_{o})} \fragment{3}{\color{in}L_{i}({\mathbf x},\,\omega_{i})}\, \fragment{5}{\color{ndl}(\omega_{i}\,\cdot\,{\mathbf n})}\, \fragment{2}{\color{int}\operatorname d\omega_{i}}$$
$$ \definecolor{out}{RGB}{219,135,217} \definecolor{emit}{RGB}{125,194,103} \definecolor{int}{RGB}{127,151,236} \definecolor{in}{RGB}{225,145,83} \definecolor{brdf}{RGB}{0,202,207} \definecolor{ndl}{RGB}{235,120,152} \definecolor{point}{RGB}{232,0,19} \color{out}L_{o}(\color{point}{\mathbf x}\color{out},\,\omega_{o})\color{black}\,=\,\color{int}\int_{\Omega} \color{brdf}f_{r}({\mathbf x},\,\omega_{i},\,\omega_{o}) \color{in}L_{i}({\mathbf x},\,\omega_{i})\, \color{ndl}(\omega_{i}\,\cdot\,{\mathbf n})\, \color{int}\operatorname d\omega_{i}$$
$$\underbrace{L_{o}({\mathbf x},\,\omega_{o})}_{\text{Radiance (Outgoing)}}\,=\,\int_{\Omega}\underbrace{f_{r}({\mathbf x},\,\omega_{i},\,\omega_{o})}_{\text{Reflectance}} \\ \underbrace{L_{i}({\mathbf x},\,\omega_{i})\, (\omega_{i}\,\cdot\,{\mathbf n})\, \operatorname d\omega_{i}}_{\text{Irradiance}}$$
$$ \definecolor{point}{RGB}{232,0,19} L_{o}({\mathbf x},\,\omega_{o})\,=\,\int_{\Omega}f_{r}({\mathbf x},\,\omega_{i},\,\omega_{o}) L_{i}(\color{point}{\mathbf x}\color{black},\,\omega_{i})\, (\omega_{i}\,\cdot\,{\mathbf n})\, \operatorname d\omega_{i}$$
$$L_{o}({\mathbf x},\,\omega_{o})\,=\,\int_{\Omega}f_{r}({\mathbf x},\,\omega_{i},\,\omega_{o}) L_{i}(\omega_{i})\, (\omega_{i}\,\cdot\,{\mathbf n})\, \operatorname d\omega_{i}$$
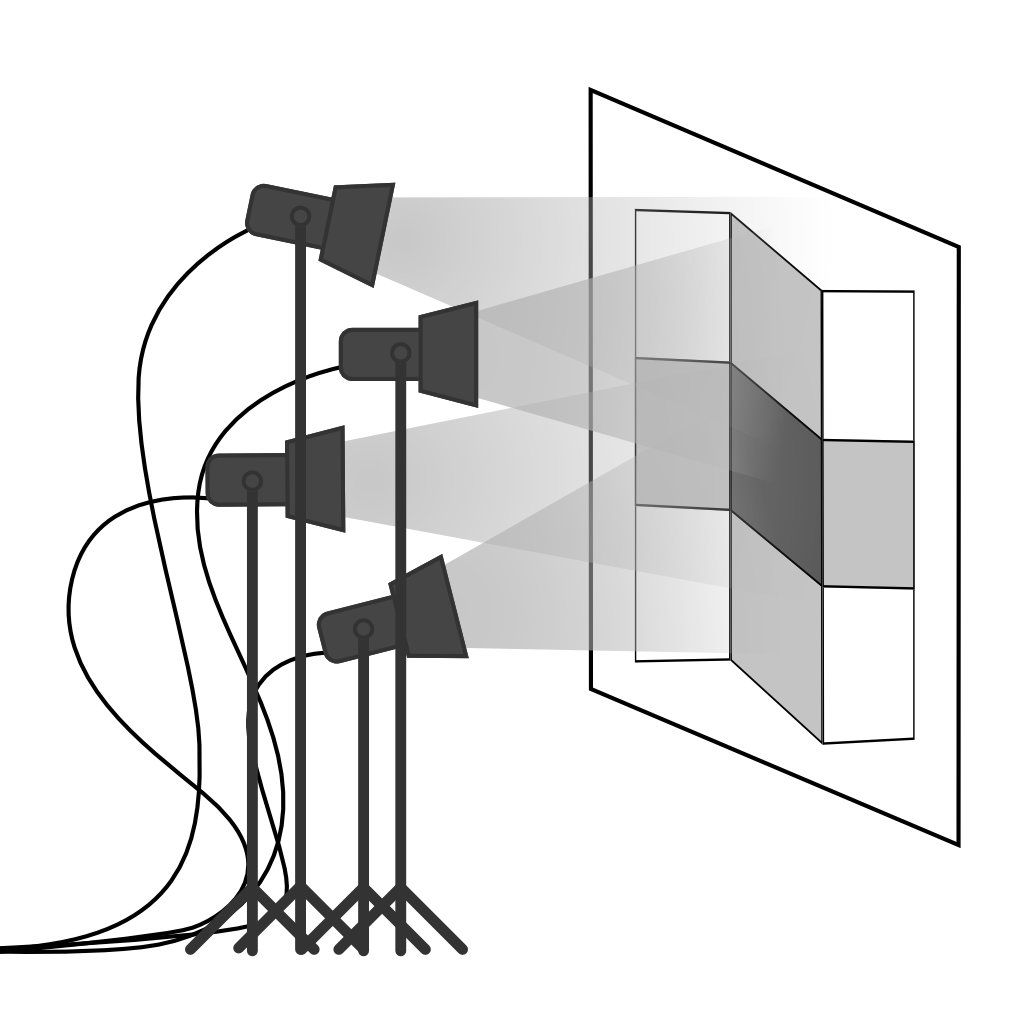
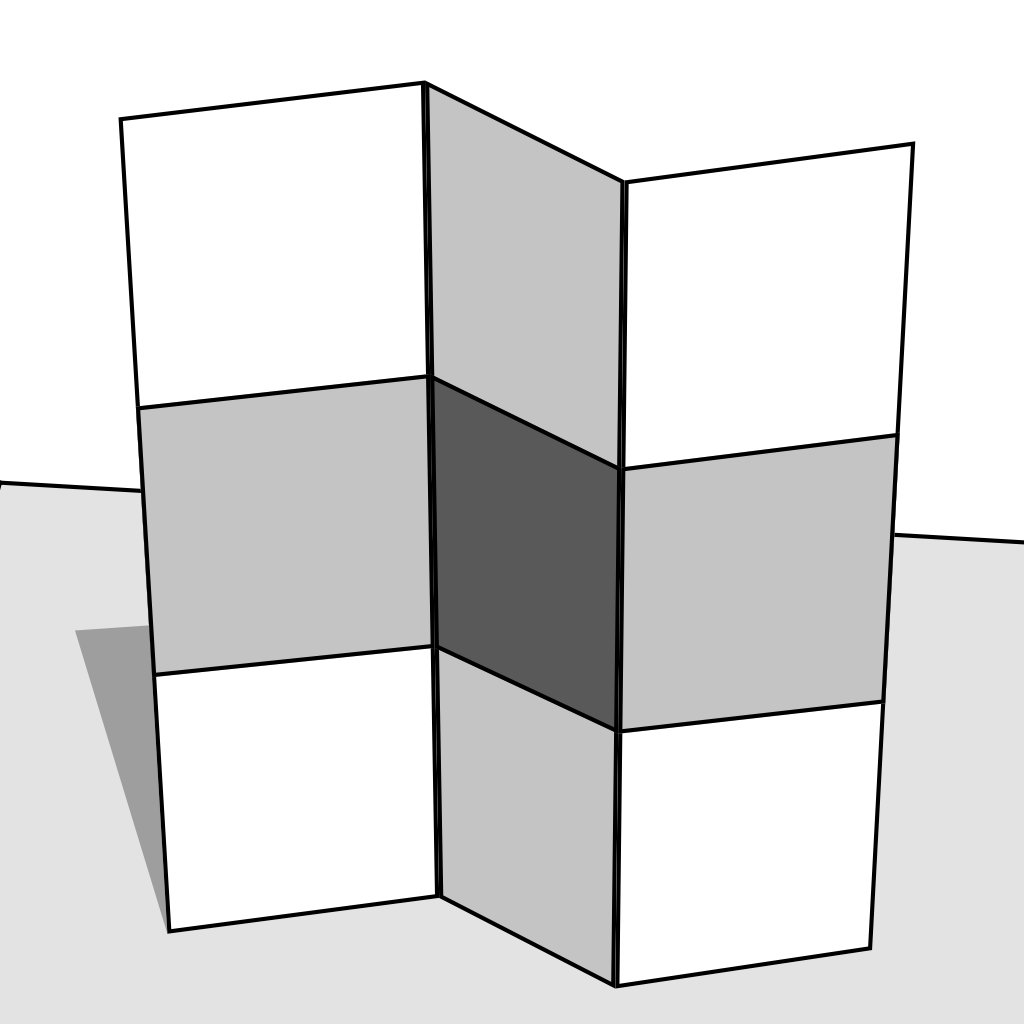
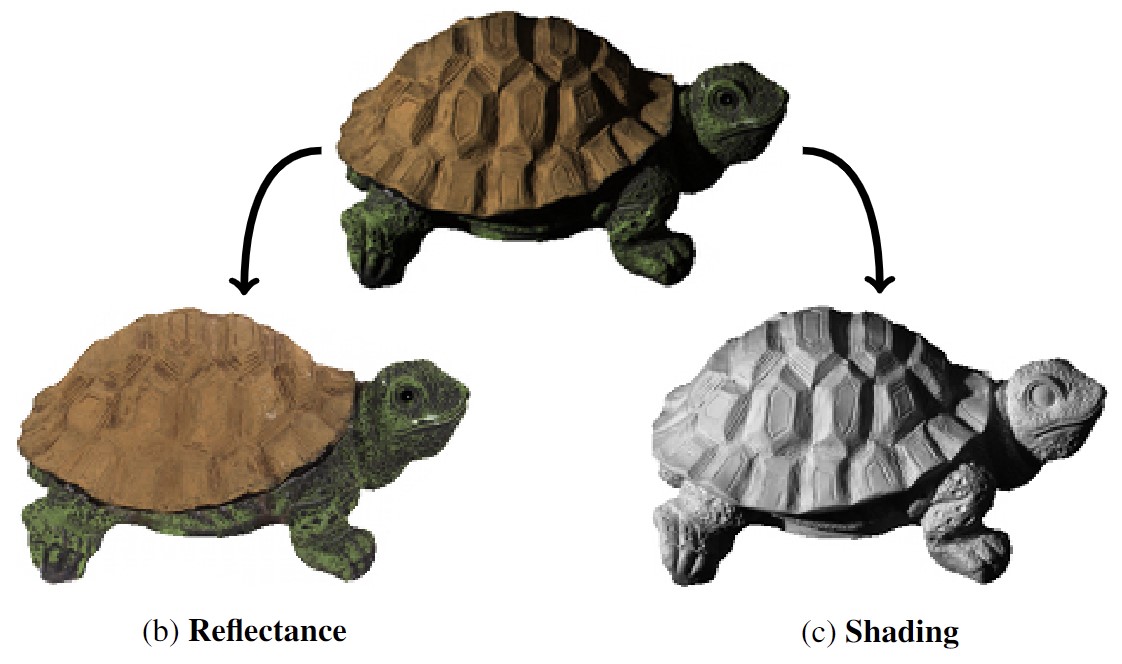
[1] E.H. Adelson, A.P. Pentland - The Perception of Shading and Reflectance - 1996

[1] Boss et al. - NeRD: Neural Reflectance Decomposition from Image Collections - 2021
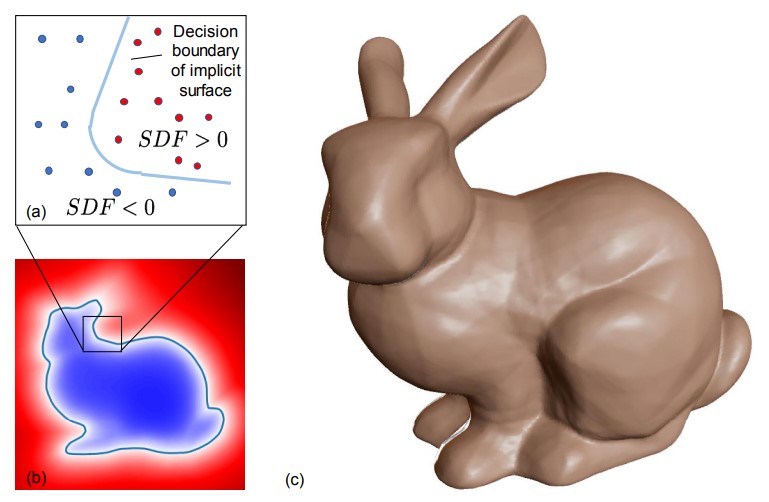
[1] Chen et al. - Learning Implicit Fields for Generative Shape Modeling - 2019
[2] Mescheder et al. - Occupancy Networks: Learning 3D Reconstruction in Function Space - 2019
[3] Park et al. - DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation - 2019
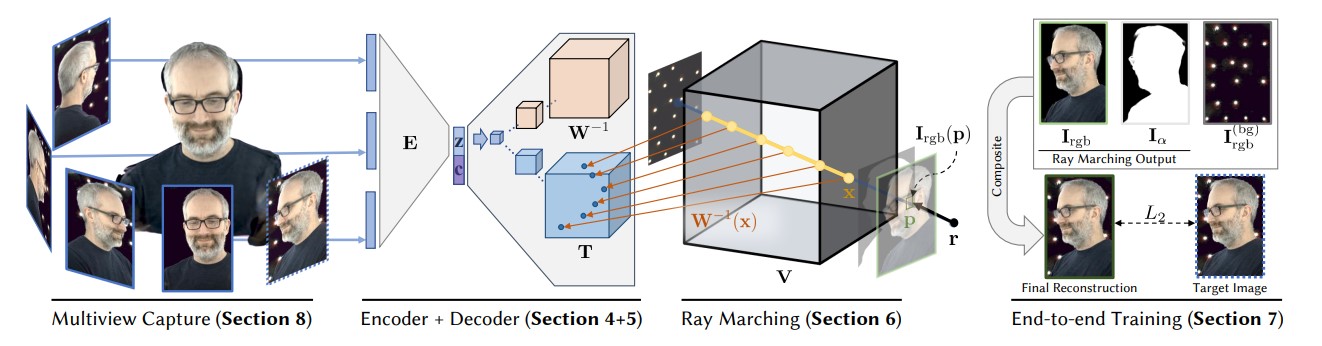
[1] Lombardi et al. - Neural Volumes: Learning Dynamic Renderable Volumes from Images - 2019
[2] Mildenhall et al. - NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis - 2020
[1] Mildenhall et al. - NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis - 2020
[1] Lombardi et al. - Neural Volumes: Learning Dynamic Renderable Volumes from Images - 2019
[2] Mildenhall et al. - NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis - 2020
[3] Martin-Brualla et al. - NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections - 2021
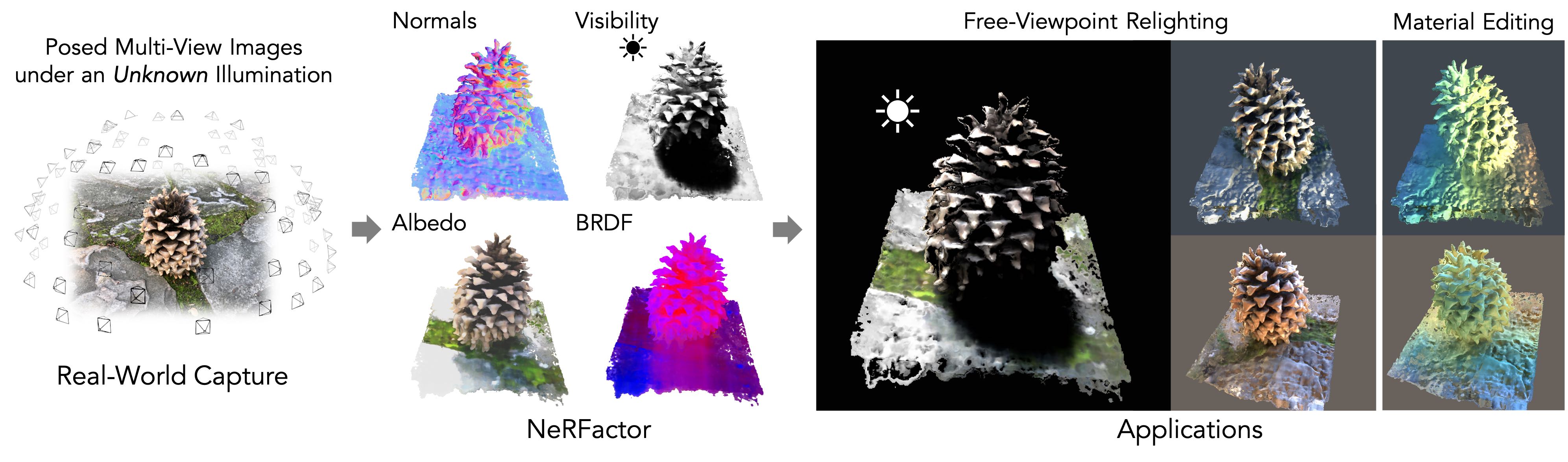
[1] Zhang et al. - PhySG: Inverse Rendering with Spherical Gaussians for Physics-based Material Editing and Relighting - 2021
[2] Srinivasan et al. - NeRV: Neural Reflectance and Visibility Fields for Relighting and View Synthesis - 2021
[3] Zhang et al. - NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown Illumination - 2021
[4] Munkberg et al. - Extracting Triangular 3D Models, Materials, and Lighting From Images - 2022
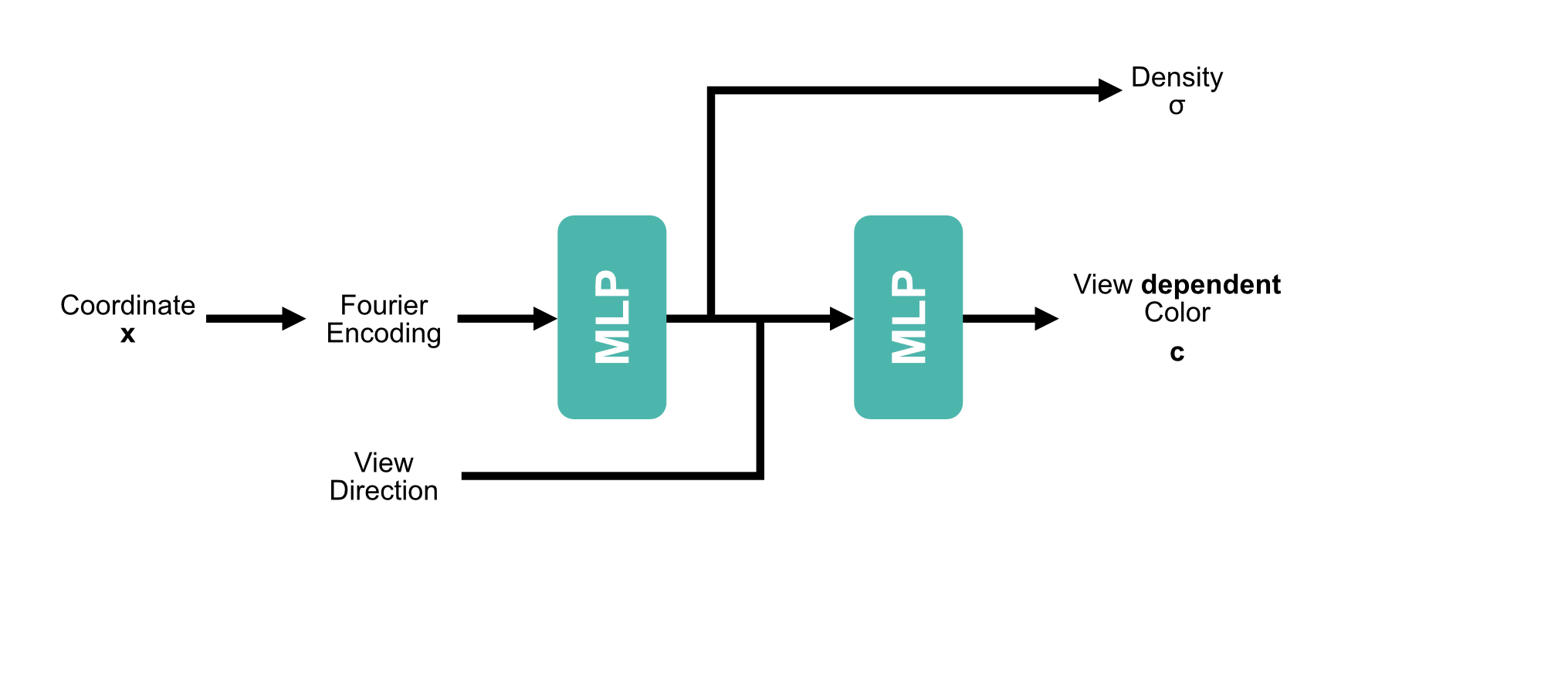
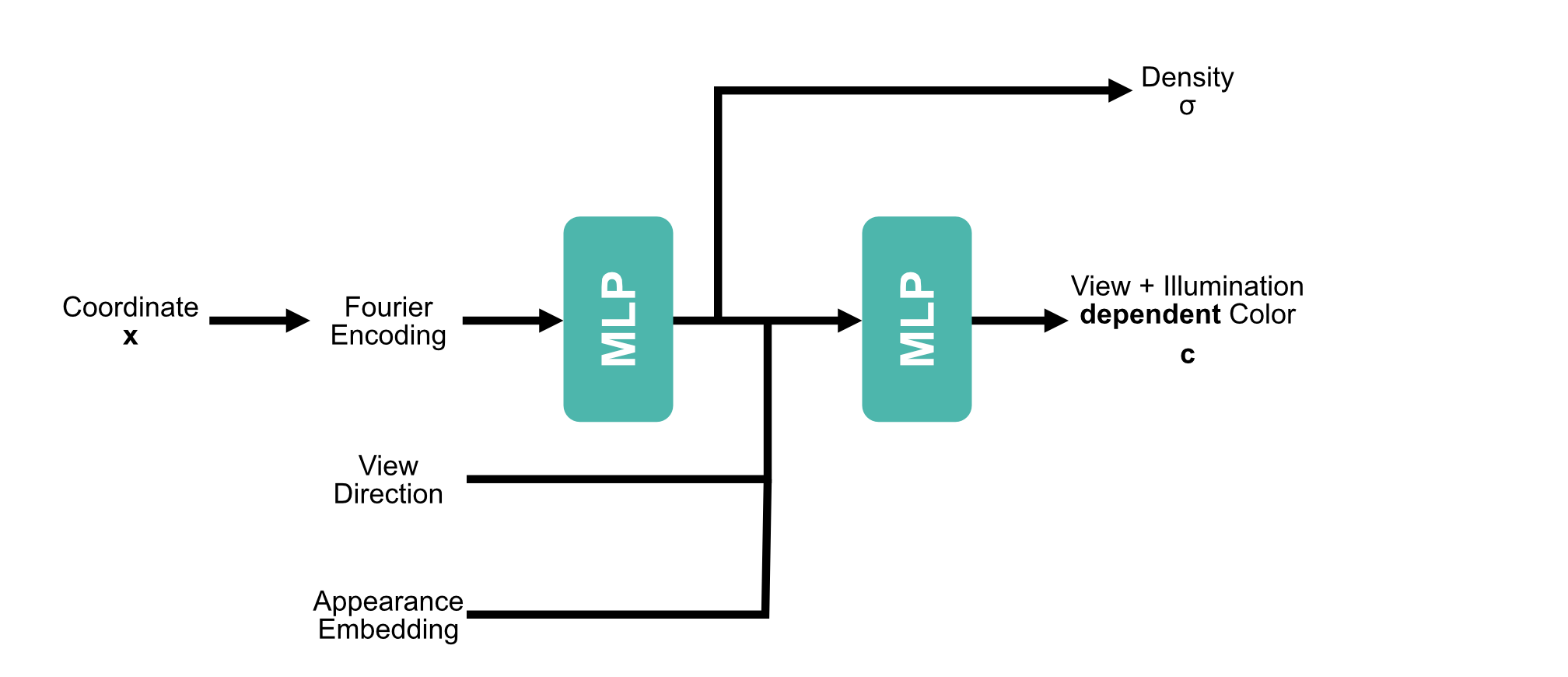
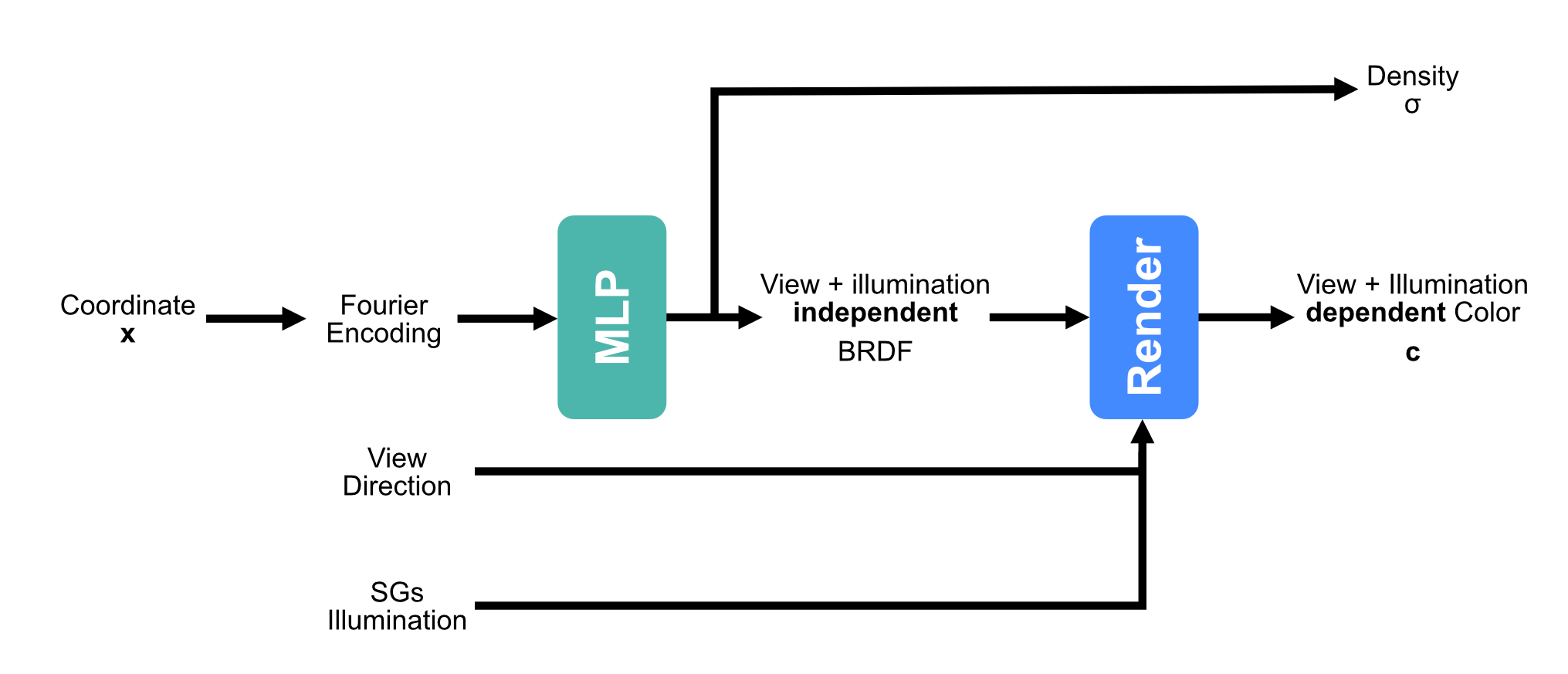
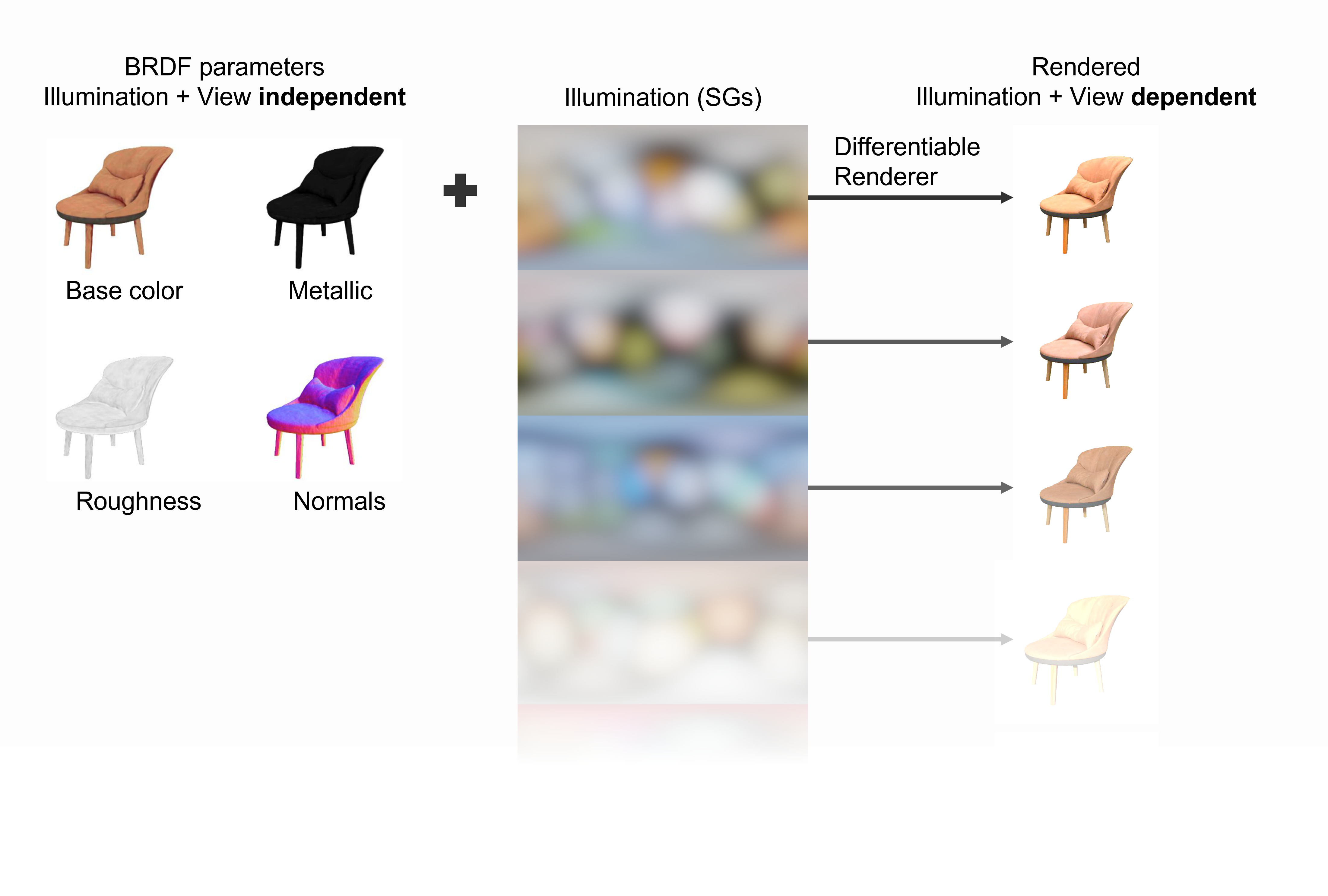



| Method | Single | Multiple |
|---|---|---|
| NeRF | 34.24 | 21.05 |
| NeRF-A | 32.44 | 28.53 |
| NeRD (Ours) | 30.07 | 27.96 |
| Method | Single | Multiple |
|---|---|---|
| NeRF | 23.34 | 20.11 |
| NeRF-A | 22.87 | 26.36 |
| NeRD (Ours) | 23.86 | 25.81 |
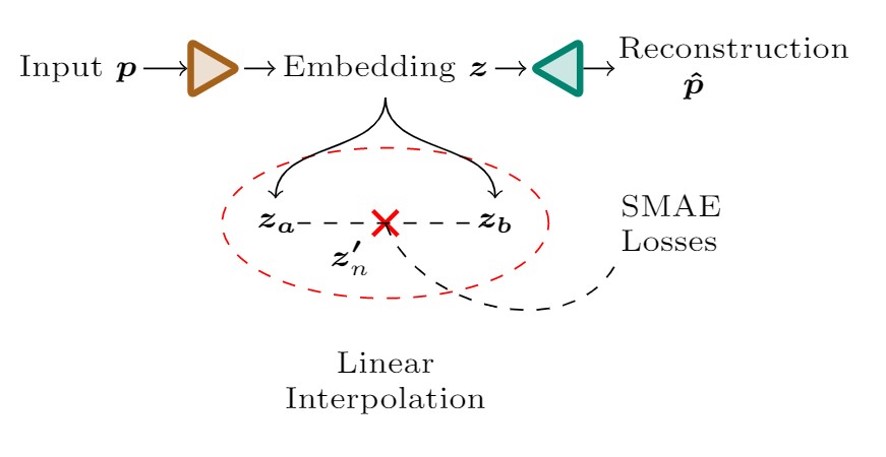
$L_o(x,\omega_o) = \underbrace{\frac{c_d}{\pi} \int_\Omega L_i(x, \omega_i) (\omega_i \cdot n) d\omega_i}_{\text{Diffuse}} + \underbrace{\int_\Omega f_r(x,\omega_i,\omega_o; c_s, c_r) L_i(x, \omega_i)(\omega_i \cdot n) d\omega_i}_{\text{Specular}}$
$L_o(x,\omega_o) = \underbrace{\frac{c_d}{\pi} \color{red}\boxed{\color{black}\int_\Omega L_i(x, \omega_i)}\color{black} (\omega_i \cdot n) d\omega_i}_{\text{Diffuse}} + \underbrace{\color{red}\boxed{\color{black}\int_\Omega}\color{black} f_r(x,\omega_i,\omega_o; c_s, c_r) \color{red}\boxed{\color{black}L_i(x, \omega_i)}\color{black} (\omega_i \cdot n) d\omega_i}_{\text{Specular}}$
$$\color{red}\boxed{\color{black}\tilde{L}_i(\omega_r, c_r)}\color{black} = \int_\Omega D(c_r, \omega_i, \omega_r)L_i(x, \omega_i)d\omega_i$$
$$L_o(x,\omega_o) \approx \underbrace{\frac{c_d}{\pi} \tilde{L}_i(n, 1)}_{\text{Diffuse}} + \underbrace{b_s (F_0(\omega_o,n)B_0(\omega_o \cdot n, c_r) + B_1(\omega_o \cdot n, c_r)) \tilde{L}_i(\omega_r, c_r)}_{\text{Specular}}$$
[1] Karis et al. - Real Shading in Unreal Engine 4
[1] Karis et al. - Real Shading in Unreal Engine 4
$$\tilde{L}_i(\omega_r, c_r) = \int_\Omega D(c_r, \omega_i, \omega_r)L_i(x, \omega_i)d\omega_i$$
| Rendering | SGs | Neural PIL |
|---|---|---|
| 1 Million Samples | 0.21s | 0.00186s |
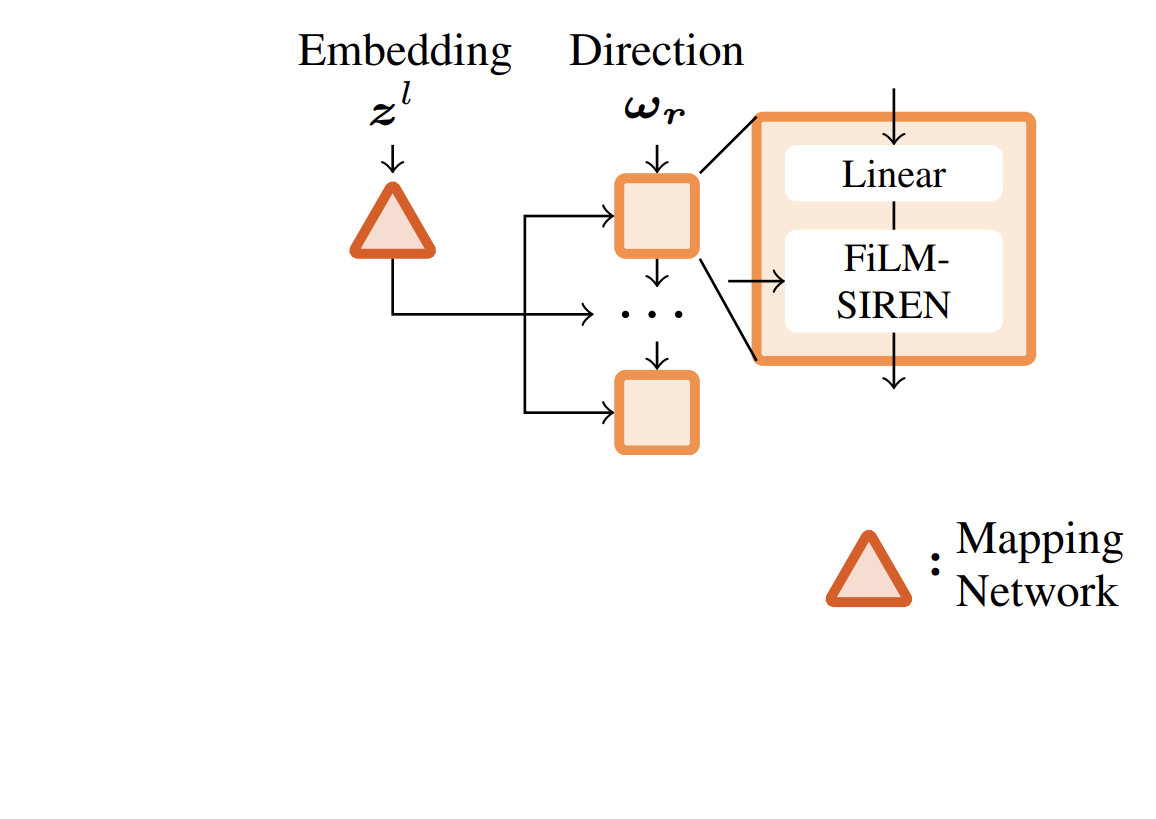
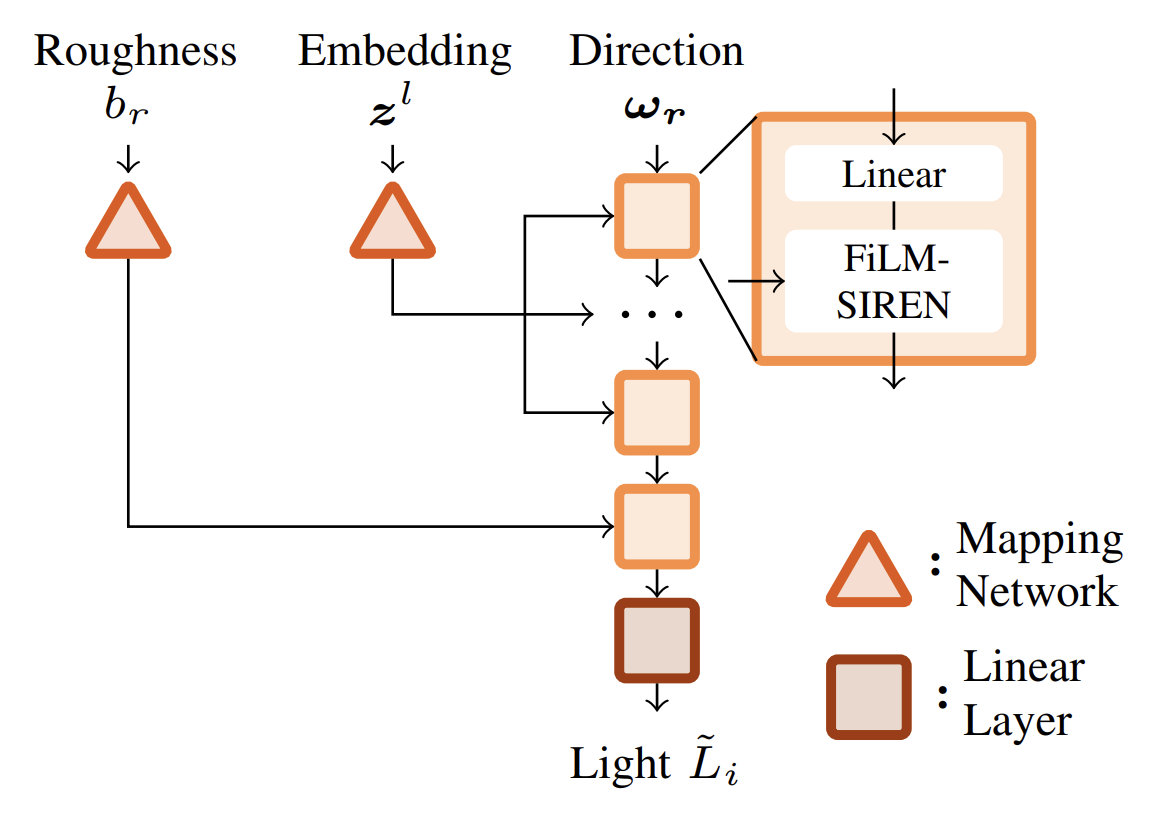
[1] Chan et al. – pi-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis - 2021










| Method | Single | Multiple |
|---|---|---|
| NeRF | 34.24 | 21.05 |
| NeRF-A | 32.44 | 28.53 |
| NeRD (Ours) | 30.07 | 27.96 |
| Neural-PIL (Ours) | 30.08 | 29.24 |
| Method | Single | Multiple |
|---|---|---|
| NeRF | 23.34 | 20.11 |
| NeRF-A | 22.87 | 26.36 |
| NeRD (Ours) | 23.86 | 25.81 |
| Neural-PIL (Ours) | 23.95 | 26.23 |






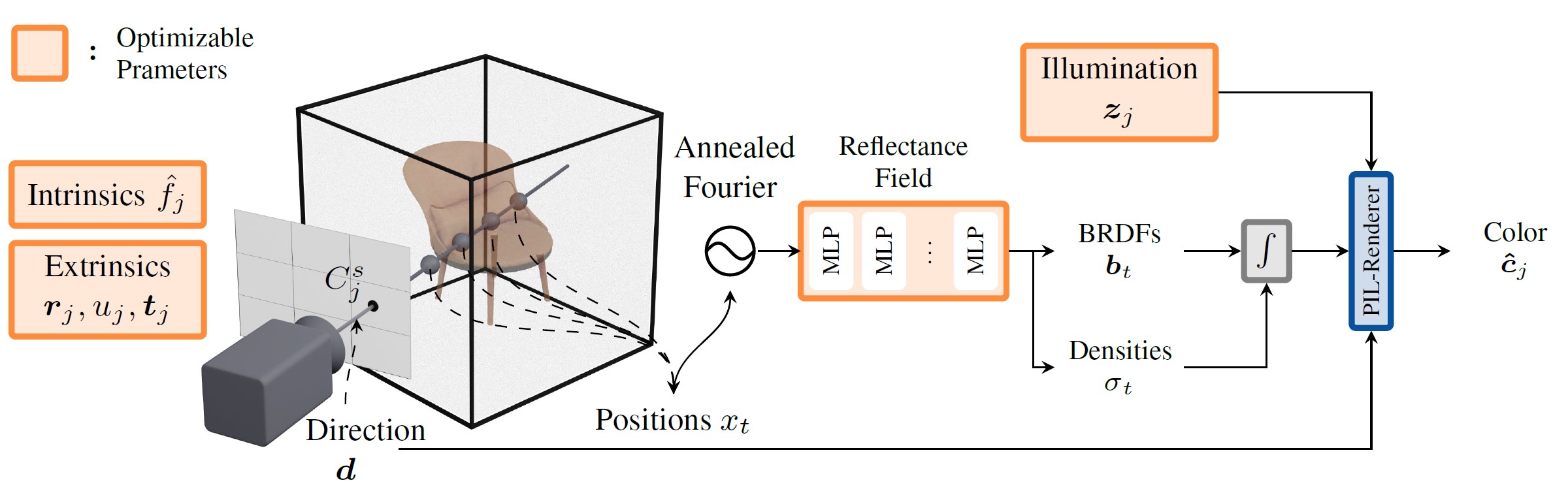
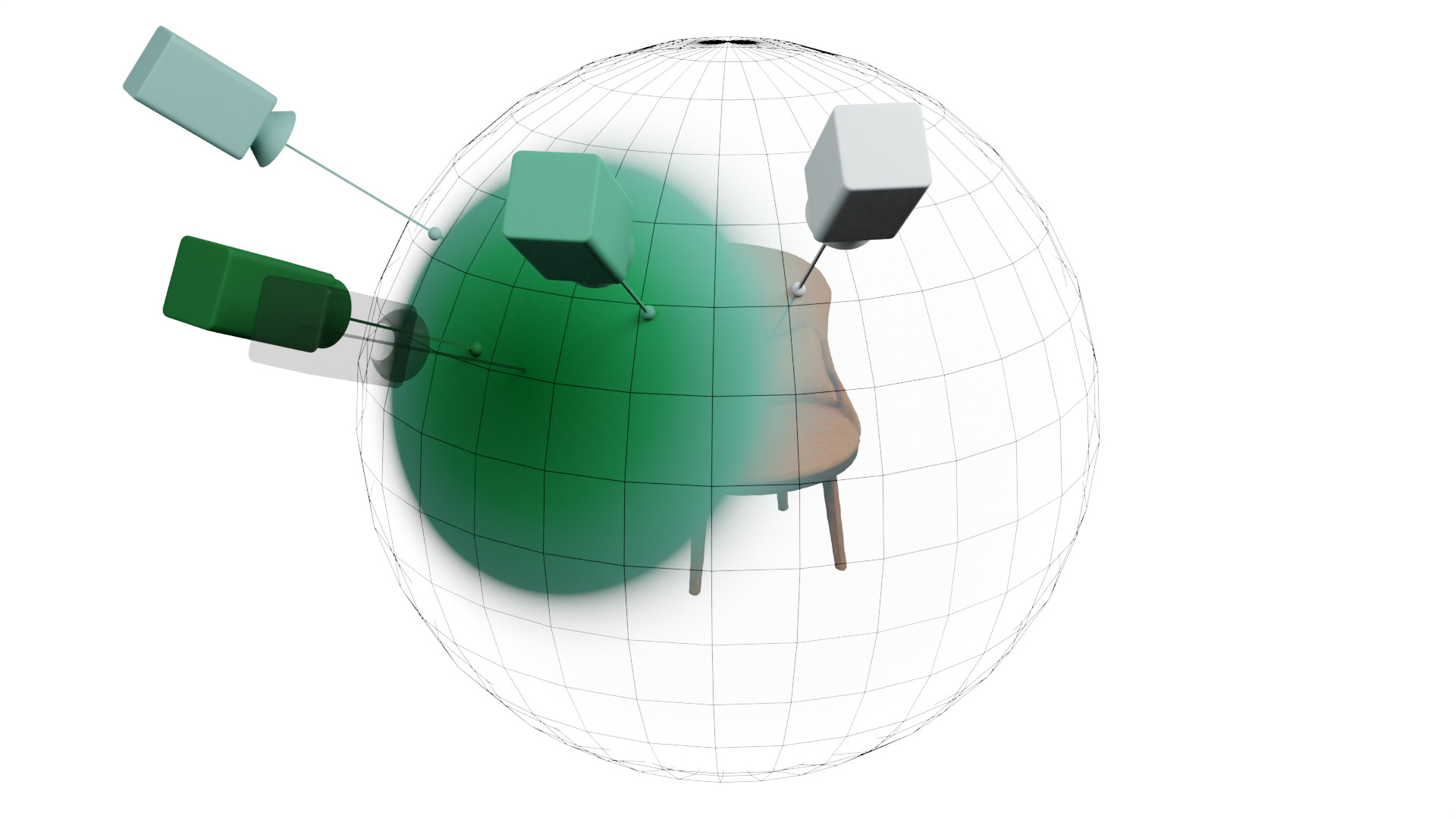
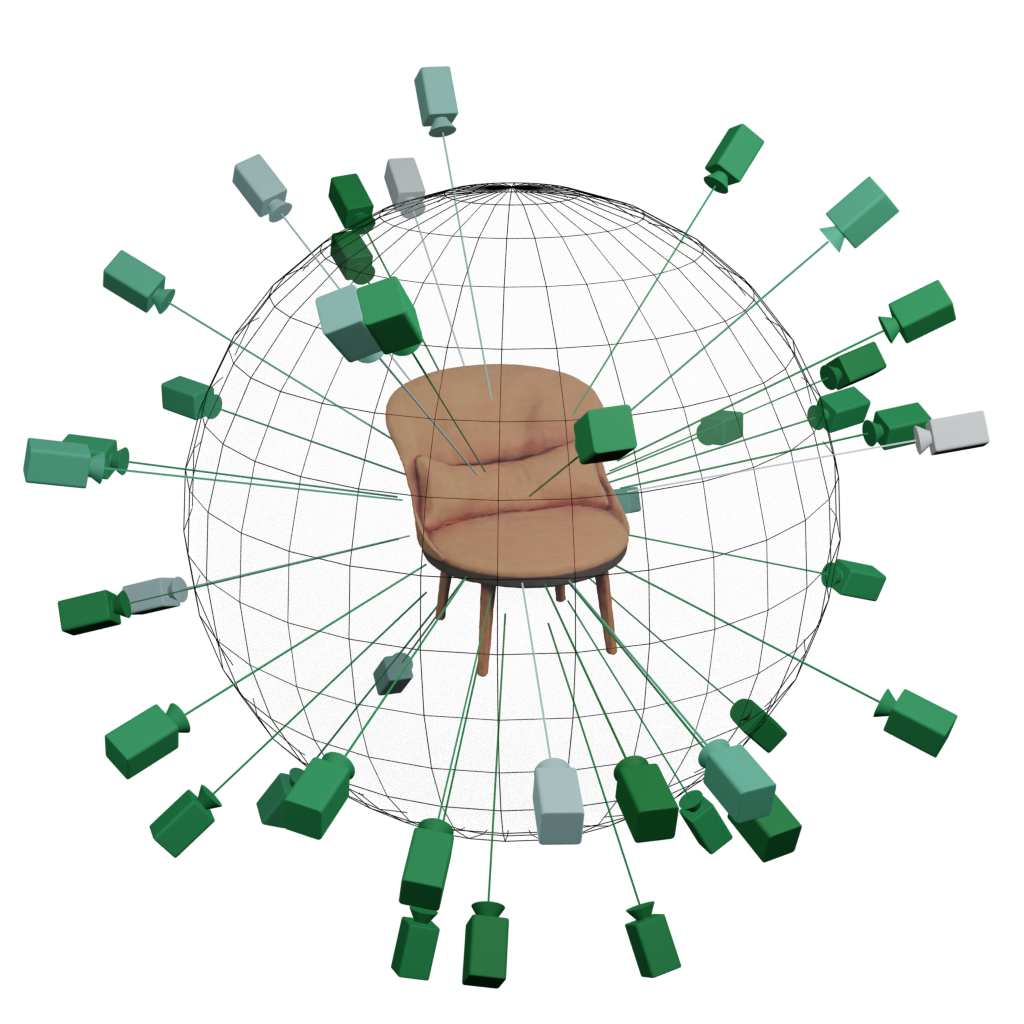

| Method | Pose Init | PSNR ↑ | Translation Error ↓ | Rotation° Error ↓ |
|---|---|---|---|---|
| BARF [1] | Directions | 14.96 | 34.64 | 0.86 |
| GNeRF [2] | Random | 20.3 | 81.22 | 2.39 |
| NeRS [3] | Directions | 12.84 | 32.77 | 0.77 |
| SAMURAI | Directions | 21.08 | 33.95 | 0.71 |
| NeRD | GT | 23.86 | — | — |
| Neural-PIL | GT | 23.95 | — | — |
[1] Lin et al. - BARF: Bundle-adjusting neural radiance fields
[2] Meng et al. - GNeRF: GAN-based Neural Radiance Field without Posed Camera
[3] Zhang et al. - NeRS: Neural reflectance surfaces for sparse-view 3d reconstruction in the wild
| Method | Pose Init | PSNR ↑ | Translation Error ↓ | Rotation° Error ↓ |
|---|---|---|---|---|
| BARF-A | Directions | 19.7 | 23.38 | 2.99 |
| SAMURAI | Directions | 22.84 | 8.61 | 0.89 |
| NeRD | GT | 26.88 | — | — |
| Neural-PIL | GT | 27.73 | — | — |
| Method | Pose Init | PSNR ↑ |
|---|---|---|
| BARF-A | Directions | 16.9 |
| SAMURAI | Directions | 23.46 |

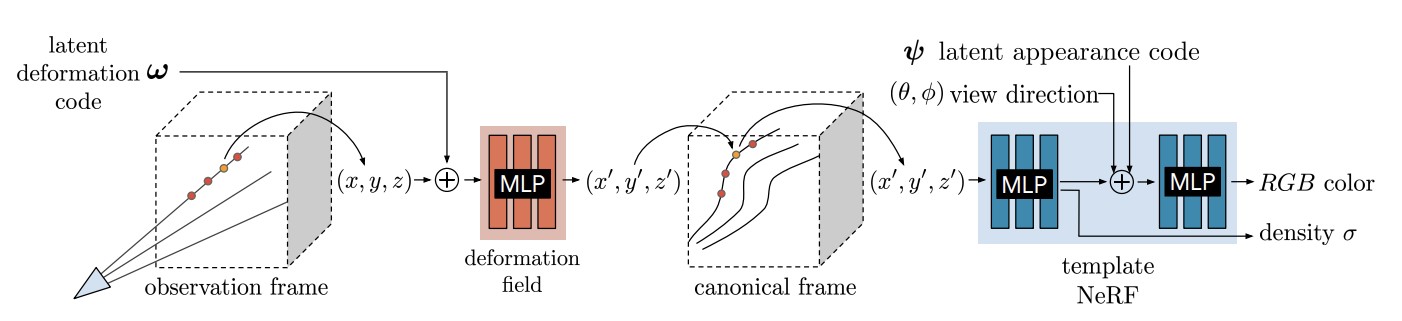
[1] Park et al. - Nerfies: Deformable Neural Radiance Fields - 2021
[2] Park et al. - A Higher-Dimensional Representation for Topologically Varying Neural Radiance Fields - 2021
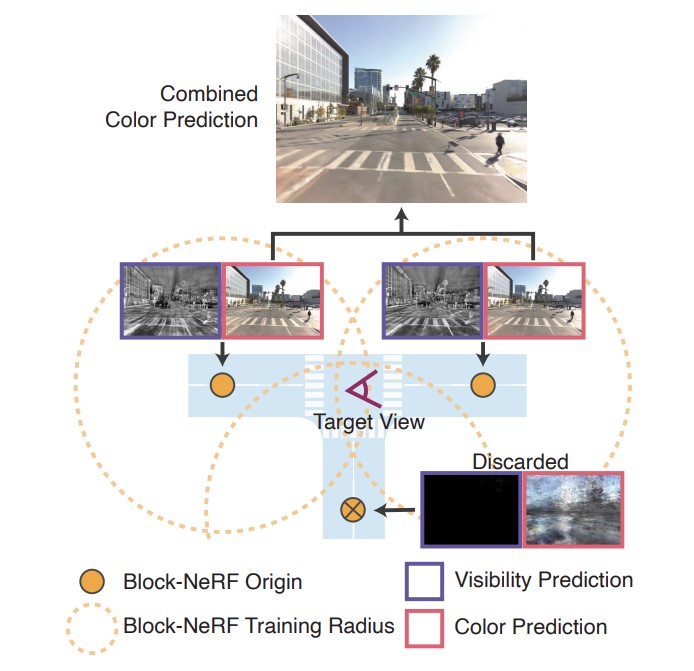
[1] Tancik et al. - Block-NeRF: Scalable Large Scene Neural View Synthesis - 2022