SV3D: Novel Multi-view Synthesis and 3D Generation from a Single Image using Latent Video Diffusion
In ECCV
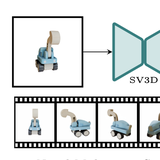
We present Stable Video 3D (SV3D) - a latent video diffusion model for high-resolution, image-to-multi-view generation of orbital videos around a 3D object. Recent work on 3D generation propose techniques to adapt 2D generative models for novel view synthesis (NVS) and 3D optimization. However, these methods have several disadvantages due to either limited views or inconsistent NVS, thereby affecting the performance of 3D object generation. In this work, we propose SV3D that adapts image-to-video diffusion model for novel multi-view synthesis and 3D generation, thereby leveraging the generalization and multi-view consistency of the video models, while further adding explicit camera control for NVS. We also propose improved 3D optimization techniques to use SV3D and its NVS outputs for image-to-3D generation. Extensive experimental results on multiple datasets with 2D and 3D metrics as well as user study demonstrate SV3D’s state-of-the-art performance on NVS as well as 3D reconstruction compared to prior works.

Collaborative Control for Geometry-Conditioned PBR Image Generation
In ECCV
Current 3D content generation builds on generative models that output RGB images. Modern graphics pipelines, however, require physically-based rendering (PBR) material properties. We propose to model the PBR image distribution directly to avoid photometric inaccuracies in RGB generation and the inherent ambiguity in extracting PBR from RGB. Existing paradigms for cross-modal finetuning are not suited for PBR generation due to a lack of data and the high dimensionality of the output modalities: we overcome both challenges by retaining a frozen RGB model and tightly linking a newly trained PBR model using a novel cross-network communication paradigm. As the base RGB model is fully frozen, the proposed method does not risk catastrophic forgetting during finetuning and remains compatible with techniques such as IPAdapter pretrained for the base RGB model. We validate our design choices, robustness to data sparsity, and compare against existing paradigms with an extensive experimental section.
SHINOBI: Shape and Illumination using Neural Object Decomposition via BRDF Optimization In-the-wild
In CVPR
We present SHINOBI, an end-to-end framework for the reconstruction of shape, material, and illumination from object images captured with varying lighting, pose, and background. Inverse rendering of an object based on unconstrained image collections is a long-standing challenge in computer vision and graphics and requires a joint optimization over shape, radiance, and pose. We show that an implicit shape representation based on a multi-resolution hash encoding enables faster and robust shape reconstruction with joint camera alignment optimization that outperforms prior work. Further, to enable the editing of illumination and object reflectance (i.e. material) we jointly optimize BRDF and illumination together with the object’s shape. Our method is class-agnostic and works on in-the-wild image collections of objects to produce relightable 3D assets for several use cases such as AR/VR, movies, games, etc.

Neural Reflectance Decomposition
Creating relightable objects from images or collections is a fundamental challenge in computer vision and graphics. This problem is also known as inverse rendering. One of the main challenges in this task is the high ambiguity. The creation of images from 3D objects is well defined as rendering. However, multiple properties such as shape, illumination, and surface reflectiveness influence each other. Additionally, an integration of these influences is performed to form the final image. Reversing these integrated dependencies is highly ill-posed and ambiguous. However, solving the task is essential, as automated creation of relightable objects has various applications in online shopping, augmented reality (AR), virtual reality (VR), games, or movies. In this thesis, we propose two approaches to solve this task. First, a network architecture is discussed, which generalizes the decomposition of a two-shot capture of an object from large training datasets. The degree of novel view synthesis is limited as only a singular perspective is used in the decomposition. Therefore, the second set of approaches is proposed, which decomposes a set of 360-degree images. These multi-view images are optimized per object, and the result can be directly used in standard rendering software or games. We achieve this by extending recent research on Neural Fields, which can store information in a 3D neural volume. Leveraging volume rendering techniques, we can optimize a reflectance field from in-the-wild image collections without any ground truth (GT) supervision. Our proposed methods achieve state-of-the-art decomposition quality and enable novel capture setups where objects can be under varying illumination or in different locations, which is typical for online image collections.

SAMURAI: Shape And Material from Unconstrained Real-world Arbitrary Image collections
In NeurIPS
Inverse rendering of an object under entirely unknown capture conditions is a fundamental challenge in computer vision and graphics. Neural approaches such as NeRF have achieved photorealistic results on novel view synthesis, but they require known camera poses. Solving this problem with unknown camera poses is highly challenging as it requires joint optimization over shape, radiance, and pose. This problem is exacerbated when the input images are captured in the wild with varying backgrounds and illuminations. In such image collections in the wild, standard pose estimation techniques fail due to very few estimated correspondences across images. Furthermore, NeRF cannot relight a scene under any illumination, as it operates on radiance (the product of reflectance and illumination). We propose a joint optimization framework to estimate the shape, BRDF, and per-image camera pose and illumination. Our method works on in-the-wild online image collections of an object and produces relightable 3D assets for several use-cases such as AR/VR. To our knowledge, our method is the first to tackle this severely unconstrained task with minimal user interaction.
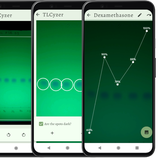
An open-source smartphone app for the quantitative evaluation of thin-layer chromatographic analyses in medicine quality screening
In Scientific Reports
Substandard and falsified medicines present a serious threat to public health. Simple, low-cost screening tools are important in the identification of such products in low- and middle-income countries. In the present study, a smartphone-based imaging software was developed for the quantification of thin-layer chromatographic (TLC) analyses. A performance evaluation of this tool in the TLC analysis of 14 active pharmaceutical ingredients according to the procedures of the Global Pharma Health Fund (GPHF) Minilab was carried out, following international guidelines and assessing accuracy, repeatability, intermediate precision, specificity, linearity, range and robustness of the method. Relative standard deviations of 2.79% and 4.46% between individual measurements were observed in the assessments of repeatability and intermediate precision, respectively. Small deliberate variations of the conditions hardly affected the results. A locally producible wooden box was designed which ensures TLC photography under standardized conditions and shielding from ambient light. Photography and image analysis were carried out with a low-cost Android-based smartphone. The app allows to share TLC photos and quantification results using messaging apps, e-mail, cable or Bluetooth connections, or to upload them to a cloud. The app is available free of charge as General Public License (GPL) open-source software, and interested individuals or organizations are welcome to use and/or to further improve this software.

Neural-PIL: Neural Pre-Integrated Lighting for Reflectance Decomposition
In NeurIPS
Decomposing a scene into its shape, reflectance and illumination is a fundamental problem in computer vision and graphics. Neural approaches such as NeRF have achieved remarkable success in view synthesis, but do not explicitly perform decomposition and instead operate exclusively on radiance (the product of reflectance and illumination). Extensions to NeRF, such as NeRD, can perform decomposition but struggle to accurately recover detailed illumination, thereby significantly limiting realism. We propose a novel reflectance decomposition network that can estimate shape, BRDF, and per-image illumination given a set of object images captured under varying illumination. Our key technique is a novel illumination integration network called Neural-PIL that replaces a costly illumination integral operation in the rendering with a simple network query. In addition, we also learn deep low-dimensional priors on BRDF and illumination representations using novel smooth manifold auto-encoders. Our decompositions can result in considerably better BRDF and light estimates enabling more accurate novel view-synthesis and relighting compared to prior art.
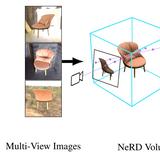
NeRD: Neural Reflectance Decomposition from Image Collections
In ICCV
Decomposing a scene into its shape, reflectance, and illumination is a challenging but important problem in computer vision and graphics. This problem is inherently more challenging when the illumination is not a single light source under laboratory conditions but is instead an unconstrained environmental illumination. Though recent work has shown that implicit representations can be used to model the radiance field of an object, most of these techniques only enable view synthesis and not relighting. Additionally, evaluating these radiance fields is resource and time-intensive. We propose a neural reflectance decomposition (NeRD) technique that uses physically-based rendering to decompose the scene into spatially varying BRDF material properties. In contrast to existing techniques, our input images can be captured under different illumination conditions. In addition, we also propose techniques to convert the learned reflectance volume into a relightable textured mesh enabling fast real-time rendering with novel illuminations. We demonstrate the potential of the proposed approach with experiments on both synthetic and real datasets, where we are able to obtain high-quality relightable 3D assets from image collections.
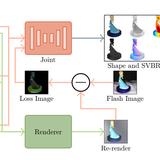
Two-shot Spatially-varying BRDF and Shape Estimation
In CVPR
Capturing the shape and spatially-varying appearance (SVBRDF) of an object from images is a challenging task that has applications in both computer vision and graphics. Traditional optimization-based approaches often need a large number of images taken from multiple views in a controlled environment. Newer deep learning-based approaches require only a few input images, but the reconstruction quality is not on par with optimization techniques. We propose a novel deep learning architecture with a stage-wise estimation of shape and SVBRDF. The previous predictions guide each estimation, and a joint refinement network later refines both SVBRDF and shape. We follow a practical mobile image capture setting and use unaligned two-shot flash and no-flash images as input. Both our two-shot image capture and network inference can run on mobile hardware. We also create a large-scale synthetic training dataset with domain-randomized geometry and realistic materials. Extensive experiments on both synthetic and real-world datasets show that our network trained on a synthetic dataset can generalize well to real-world images. Comparisons with recent approaches demonstrate the superior performance of the proposed approach.
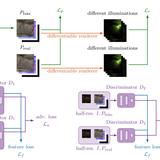
Single Image BRDF Parameter Estimation with a Conditional Adversarial Network
Creating plausible surfaces is an essential component in achieving a high degree of realism in rendering. To relieve artists, who create these surfaces in a time-consuming, manual process, automated retrieval of the spatially-varying Bidirectional Reflectance Distribution Function (SVBRDF) from a single mobile phone image is desirable. By leveraging a deep neural network, this casual capturing method can be achieved. The trained network can estimate per pixel normal, base color, metallic and roughness parameters from the Disney BRDF. The input image is taken with a mobile phone lit by the camera flash. The network is trained to compensate for environment lighting and thus learned to reduce artifacts introduced by other light sources. These losses contain a multi-scale discriminator with an additional perceptual loss, a rendering loss using a differentiable renderer, and a parameter loss. Besides the local precision, this loss formulation generates material texture maps which are globally more consistent. The network is set up as a generator network trained in an adversarial fashion to ensure that only plausible maps are produced. The estimated parameters not only reproduce the material faithfully in rendering but capture the style of hand-authored materials due to the more global loss terms compared to previous works without requiring additional post-processing. Both the resolution and the quality is improved.