SHINOBI: Shape and Illumination using Neural Object Decomposition via BRDF Optimization In-the-wild
Abstract
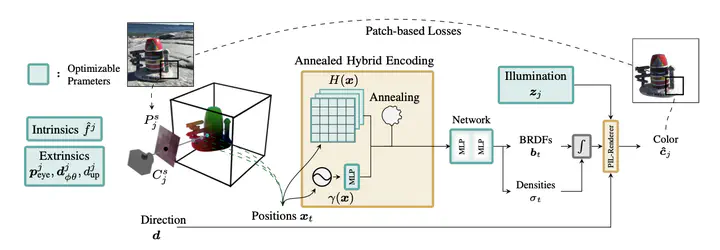
We present SHINOBI, an end-to-end framework for the reconstruction of shape, material, and illumination from object images captured with varying lighting, pose, and background. Inverse rendering of an object based on unconstrained image collections is a long-standing challenge in computer vision and graphics and requires a joint optimization over shape, radiance, and pose. We show that an implicit shape representation based on a multi-resolution hash encoding enables faster and robust shape reconstruction with joint camera alignment optimization that outperforms prior work. Further, to enable the editing of illumination and object reflectance (i.e. material) we jointly optimize BRDF and illumination together with the object’s shape. Our method is class-agnostic and works on in-the-wild image collections of objects to produce relightable 3D assets for several use cases such as AR/VR, movies, games, etc.
Mark Boss
Research Scientist
I’m a researcher at Stability AI with research interests in the intersection of machine learning and computer graphics.