NeRF at NeurIPS 2022
Inspired by Frank Dellaert and his excellent series on the original NeRF Explosion and the following ICCV/CVPR conference gatherings, I decided to look into creating a NeurIPS 22 rundown myself.
The papers below are all the papers I could gather by browsing through the extensive list of accepted NeurIPS papers. I mainly collected all papers where the titles fit and did a brief scan through the paper or only the abstract if the paper wasn’t published at the time of writing. If I have mischaracterized or missed any paper, please send me a DM on Twitter @markb_boss or via mail.
Note: images below belong to the cited papers, and the copyright belongs to the authors or the organization that published these papers. Below I use key figures or videos from some papers under the fair use clause of copyright law.
NeRF
Mildenhall et al. introduced NeRF at ECCV 2020 in the now seminal Neural Radiance Field paper. As mentioned in the introduction, there has been fantastic progress in research in this field. NeurIPS this year is no exception to this trend.
What NeRF does, in short, is similar to the task of computed tomography scans (CT). In CT scans, a rotating head measures densities from x-rays. However, knowing where that measurement should be placed in 3D is challenging. NeRF also tries to estimate where a surface and view-dependent radiance is located in space. This is done by storing the density and radiance in a neural volumetric scene representation using MLPs and then rendering the volume to create new images. With many posed images, photorealistic novel view synthesis is possible.
Rotate by clicking and dragging, zoom via mouse wheel, and use the buttons (Teal indicates active) to visualize the NeRF process.
Fundamentals

These address more fundamental areas of view-synthesis with NeRF methods.
NTRF extends NeRF to improve transmission and reflections, using neural transmittance fields and edge constraints.
PNF introduces a new class of neural fields using basis-encoded polynomials. These can represent the signal as a composition of manipulable and interpretable components.
LoENerf introduces a Levels-of-Experts (LoE) framework to create a novel coordinate-based representation with an MLP. The weights of the MLP are hierarchical, periodic, and position-dependent. Each layer of the MLP has multiple candidate values of the weight matrix, which are individually tiled across the input space.
Improved surface reconstruction using high-frequency details can be achieved by splitting the base low-frequency shape into signed distance fields and the high-frequent details in a deformation field on the base shape.
Generalised Implicit Neural Representations venture far beyond the realm of euclidean coordinate systems and propose to observe the continuous high dimensional signal as a discrete graph and perform a spectral embedding on each node to establish the input for the neural field.
Geo-Neus introduces explicit multi-view geometry constraints to generate geometry consistent surface reconstructions. These losses include ones for signed distance function (SDF) from sparse structure-from-motion (SFM) point clouds and ones for photometric consistency.
While SDFs are often used to express geometry in NeRFs, they can only represent closed shapes. Using unsigned distance functions (UDF) can express open and watertight surfaces, but they can pose challenges in meshing. HSDF presents a learnable representation that combines the benefits of each.
Audio

As sound propagates similar to rays in a volume, NeRF also found usage in this area.
INRAS stores high-fidelity time domain impulse responses at arbitrary positions using neural fields. This allows modeling spatial acoustic for a scene efficiently.
NAF follow a similar approach to INRAS, learning impulse response functions in spatially varying scene.
Priors and Generative

Priors can either aid in the reconstruction or can be used in a generative manner. For example, in the reconstruction, priors either increase the quality of neural view synthesis or enable reconstructions from sparse image collections.
In CoCo-INR, two attention modules are used. One to extract useful information from the prior codebook and the other to encode these entries into the scene. With this prior, the method is capable of working on sparse images.
In sparse image collections, several areas are often rarely observed. To circumvent this issue, NeuForm relies on generalizable category-specific representation in less observed areas. In well-observed areas, the method uses the accurate overfitting of NeRF.
MonoSDF integrates recent monocular depth and normal prediction networks as priors. Given these additional priors, the authors show performance improvement under either MLP neural fields or voxel-based grid methods.
VoxGRAF combines recent methods for speeding up NeRFs using voxel-based structures and 3D convolutions to generate novel objects in a single forward pass. These scenes can then be rendered from any viewpoint.
Articulated
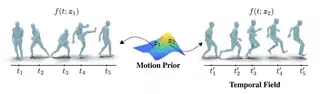
Capturing dynamic objects is a trend that started in previous conference years. However, this year I noticed a trend in adding priors.
Neural Shape Deformation Priors uses a transformer trained on large datasets to learn a prior of non-rigid transformations. A source mesh can be morphed with a continuous neural deformation field to a target mesh with a partially described surface deformation.
NeMF learns a prior of human and quadruped motion and uses it generatively in a neural motion field. The authors show use cases for motion interpolation or in-betweening.
DeVRF proposes to use 3D spatial voxel grids alongside a 4D deformation field to model dynamic scenes in a highly efficient manner.
FNeVR enables animating faces with NeRFs by combining 2D motion warping with neural rendering.
NDR jointly optimizes the surface and deformation from a dynamic scene using monocular RGB-D cameras. They propose an invertible deformation network to provide cycle consistency between frames. As the topology might change in dynamic scenes, they also employ a strategy to generate topology variants.
Editable and Composable
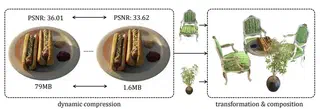
This section covers NeRFs that provide methods for composing, controlling, or editing.
D2NeRF learns a decoupling of static and dynamic objects from monocular video. Here, two networks are trained separately, which handle the respective areas.
NeuPhysics allows editing a dynamic scene by editing physics parameters. This editing is performed on a hexahedra mesh tied to an underlying neural field in a two-way conversion. The physics simulation is done differently on the mesh and can propagate back to the neural field.
CageNeRF uses low-poly cages around the object to create a simple deformation target. Deforming the cage is then simple in manual editing. The deformation can then be used to warp the previously trained NeRF.
INSP-Net introduces signal processing into neural fields by introducing a differential operator framework, which can directly work on the fields without discretization. The authors even propose a CovnNet running on the neural representation.
Decomposing NeRF for Editing via Feature Field Distillation uses existing 2D feature extractors such as CLIP-LSeg to provide additional supervision to detect semantics in the 3D volume. Users can query based on text, image patches, or direct pixel selection to allow semantic editing.
CCNeRF uses a tensor rank decomposition to express the neural fields in a highly efficient and compressible manner. As the representation is explicit, the learned models are also composable.
Decomposition
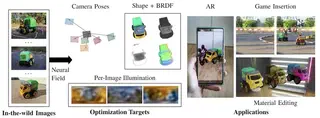
In this section, the radiance of NeRF is split into geometry, BRDF, and illumination. This enables consistent relighting under any illumination.
RENI uses SIREN and vector neurons to learn a neural prior on natural HDR illuminations. They extend the vector neurons to handle rotation equivariance for spherical images.
Neural Reflectance Field from Shading and Shadow under a Fixed Viewpoint leverages a fixed viewpoint with a moving light source. This way, the geometry, and BRDF have to be recovered based on shading cues. Due to the neural fields, the 3D scene is recovered even from the fixed viewpoint.
In Shape, Light & Material Decomposition from Images using Monte Carlo Rendering and Denoising no previously used low-frequency basis or pre-integration is used to express the environment illumination. Instead, regular Monte Carlo integration is used, which is passed through a denoising network to ease the learning process from noisy gradients.
In SAMURAI the model can decompose coarsely posed image collections into shape, BRDF, and illumination. The cameras are also optimized during training with a camera multiplex. Especially, datasets of challenging scenes where traditional SFM methods fail can be decomposed with this method. For transparency, I’m the author of the paper
Other
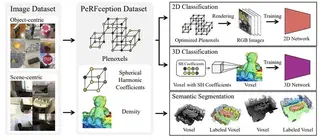
Several works with excellent results in various fields.
NeMF proposes to leverage neural fields for semantic correspondence matching. A coarse cost volume is used to guide a high-precision neural matching field.
SNAKE proposes introducing shape reconstruction with neural fields to aid in 3D keypoint detection for point clouds. No supervision for the detection is required.
Segmentation and concept learning in NeRFs can benefit from 3D Concept Grounding on Neural Fields, where a high-dimensional feature descriptor at each spatial location is taken from language embeddings.
ULNef specifically targets virtual try-on settings where multiple garments are layered. These layers are modeled as neural fields, and the collision handling is directly performed on the fields.
In NeRF-RL, a neural field is used to learn a latent space as the state representation for the reinforcement learning algorithm.
PeRFception establishes new large-scale datasets for perception-related tasks such as segmentation, classification, etc. They also evaluate a plenoxels variant on these datasets.
Conclusion
This was quite the amount of work, and I have enormous respect for Frank Dellaert for having it done thrice before. The field of NeRF moves incredibly fast, and even for a single conference, there exists a massive amount of reading material.
It is also interesting to see NeRF find new applications in other fields such as audio and that sorting papers into a single category becomes challenging. This might be related to fast progress in the field and the high risk of getting scooped.
