NeRF at ECCV 2022
I recently went through the the provisional programm of ECCV 2022. After my last post on “NeRF at NeurIPS” got such great feedback, and I anyway compiled a list of all NeRFy things, I decided to do it all again.
I again tried to find all papers by parsing the titles of the provisional program. A brief scan through the paper or abstract was then done to confirm if it is NeRFy and get a rough idea about the paper. If I have mischaracterized or missed any paper, please send me a DM on Twitter @markb_boss or via mail.
Here we go again!
Note: images below belong to the cited papers, and the copyright belongs to the authors or the organization that published these papers. Below I use key figures or videos from some papers under the fair use clause of copyright law.
NeRF
Mildenhall et al. introduced NeRF at ECCV 2020 in the now seminal Neural Radiance Field paper. As mentioned in the introduction, there has been fantastic progress in research in this field. NeurIPS this year is no exception to this trend.
What NeRF does, in short, is similar to the task of computed tomography scans (CT). In CT scans, a rotating head measures densities from x-rays. However, knowing where that measurement should be placed in 3D is challenging. NeRF also tries to estimate where a surface and view-dependent radiance is located in space. This is done by storing the density and radiance in a neural volumetric scene representation using MLPs and then rendering the volume to create new images. With many posed images, photorealistic novel view synthesis is possible.
Rotate by clicking and dragging, zoom via mouse wheel, and use the buttons (Teal indicates active) to visualize the NeRF process.
Fundamentals
Light field distillation with R2L. Here, on the left, the regular NeRF rendering is compared with the distilled light field. The quality improves with the light field (NeRF PSNR: 28.11 vs. R2L PSNR: 34.18).
These papers address more fundamental problems of view-synthesis with NeRF methods.
Typically in streaming, the quality of the signal is adjusted depending on the connection quality. NeRFs, on the other hand, encode the entire signal in the weights. Streamable Neural Fields aims to fix that by encoding everything into smaller sub-networks that can be streamed over time.
While NeRFs provide photorealistic novel view synthesis results, they do not offer a way to estimate the certainty of their reconstruction. Especially in medical or autonomous driving, this is a highly desirable property. Conditional-Flow NeRF aims to alleviate this by leveraging a flexible data-driven approach with conditional normalizing flows coupled with latent variable modeling.
R2L aims to directly learn a surface light field from a pre-trained NeRF. This way, only a single point per ray needs to be evaluated, drastically improving the inference performance.
AdaNeRF aims to speed up NeRF rendering by learning to reduce the sample count drastically using a split network architecture. One network predicts the sampling, and the other the shading. By enforcing sparsity during training, the number of samples can be lowered.
Intrinsic Neural Fields proposes a new representation for neural fields on manifolds using the spectral properties of the Laplace-Beltrami operator.
Beyond Periodicity examines the activation functions of NeRFs and tests several novel non-periodic activation functions which enable high-frequency signal encoding.
NeDDF proposes a novel 3D representation that reciprocally constrains the distance and density fields. This enables the definition of a distance field for objects with indefinite boundaries (smoke, hairballs, glass, etc.) without losing density information.
BungeeNeRF enables training NeRFs on large-scale scenes by growing the network during training with a residual block structure. Each block progressively encodes a finer scale.
SNeS proposes to leverage symmetry during NeRF training for unseen areas of objects. Geometry and material are often symmetrical, but illumination and shadowing are not symmetric. Therefore, the method introduces a soft symmetry constraint for geometry and materials and includes a global illumination model which can break the symmetry.
HDR-Plenoxels learns an HDR radiance field with multiple LDR images under different camera settings. The method achieves this by modeling the tone mapping of camera imaging pipelines.
MINER enables gigapixel image or large-scale point cloud learning with Laplacian pyramids to learn multi-scale signal decompositions. Small MLPs learn disjointed patches in each pyramid scale, and the scales allow the network to grow in capacity during training.
Priors and Generative

Priors can either aid in the reconstruction or can be used in a generative manner. For example, in the reconstruction, priors either increase the quality of neural view synthesis or enable reconstructions from sparse image collections.
ShAPO aims to solve the challenge of 3D understanding from a single RGB-D image by posing the problem as a latent space regression of shape, appearance, and pose latent codes.
KeypointNeRF aims to represent general human avatars with NeRFs by encoding relative spatial 3D information from sparse 3D keypoints. These keypoints are easily applicable with human priors to novel avatars or capture setups.
DFRF uses NeRFs to tackle talking head synthesis, which is the task of animating a head from audio. Here, the NeRF is conditioned on 2D appearance and audio features. This also acts as a prior and enables fast adjustments to novel identities.
SparseNeuS enables reconstructions from sparse images by learning generalizable priors from image features by introducing geometry encoding volumes for generic surface prediction.
Scene-DRDF predicts a full 3D scene from a single unseen image. For this, the method is trained on a dataset of realistic non-watertight scans of scenes and predicts the Directed Ray Distance Function (DRDF).
In Generalizable Patch-Based Neural Rendering, the color of a ray in a novel scene is predicted directly from a collection of patches sampled from the scene. The method leverages epipolar geometry to extract patches along the epipolar line, linearly projects them into a 1D feature vector, and transformers process the collection.
ViewFormer proposes tackling the novel view synthesis task from 2D images in a single pass network. Here, a two-stage architecture consisting of a codebook and a transformer model is used. The former is used to embed individual images into a smaller latent space, and the transformer solves the view synthesis task in this more compact space.
Transformers as Meta-Learners for Implicit Neural Representations proposes to leverage transformers as hyper networks for neural fields, which generate the weights of the NeRF. This circumvents the information bottleneck of only conditioning the field based on a single latent vector.
Sem2NeRF reconstructs a 3D scene from a single-view semantic mask. This is achieved by encoding the mask into a latent code that controls the scene representation of a pre-trained decoder.
CompNVS proposes to perform novel view synthesis from RGB-D images with largely incomplete scene coverage. The method works on a grid-based representation and completes unobserved parts with pre-trained networks.
SiNeRF trains a NeRF from a single view by applying geometric and semantic regularizations. Here, image warping is used to obtain geometry pseudo labels, and adversarial training, as well as a pre-trained ViT, are utilized for semantic pseudo labels
There exists a large body of GANs which are not 3D aware. Generative Multiplane Images asks how to modify the existing body of work to be 3D aware with as few modifications as possible.
Articulated
Motion estimation with PREF. PREF is capable of motion estimation even under topological changes.
Capturing dynamic objects is a trend that started in previous conference years. However, this year I noticed a trend in adding neural priors.
PREF learns a neural motion field by introducing regularization on the predictability of motion based on previous frames using a predictor network.
ARAH enables learning animated clothed human avatars from multi-view videos. These avatars have pose-dependent geometry and appearance and generalize to out-of-distribution poses.
NeuMan proposes a framework to reconstruct humans and scenes from a single video with a moving camera. Separate training for the scene and the human is performed, and a warping field to the canonical dynamic human is learned.
Finding a correspondence between two non-rigidly deforming shapes is a challenging task, which Implicit field supervision for robust non-rigid shape matching proposes to solve with an auto-decoder framework, which learns a continuous shape-wise deformation field.
AutoAvatar extends recent avatar modeling with autoregressive modeling to express dynamic effects such as soft-tissue deformation.
Pose-NDF learns a prior of human motion as a field of high-dimensional SO(3)$^K$ pose definition with $K$ quaternions. The resulting manifold can then be easily interpolated and create novel poses.
DANBO introduces two inductive biases to enable learning of robust body geometry: Exploiting body part dependencies defined by the skeleton structure using Graph Neural Networks, and each bone predicts a part-specific volume that encodes the local geometry feature. A final aggregation network blends the associated voxel features and creates the neural field.
Editable and Composable
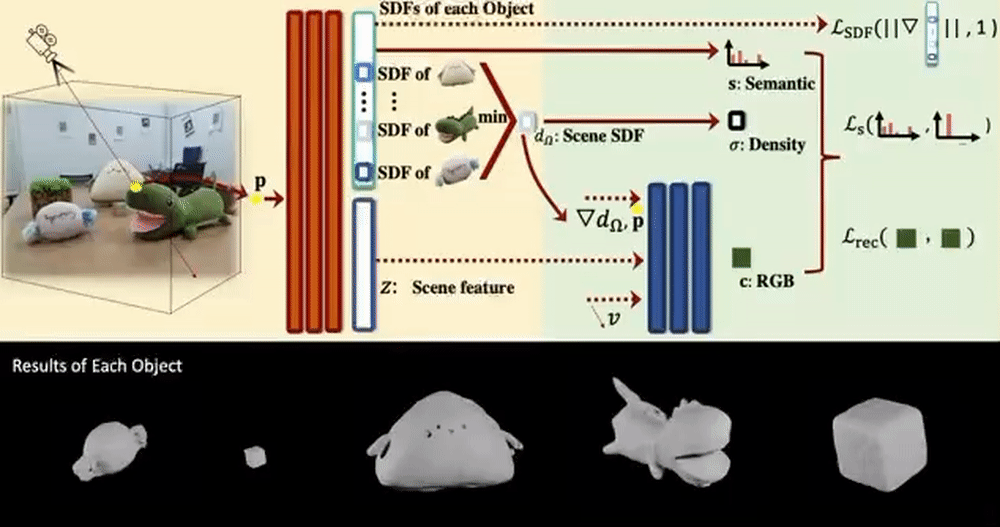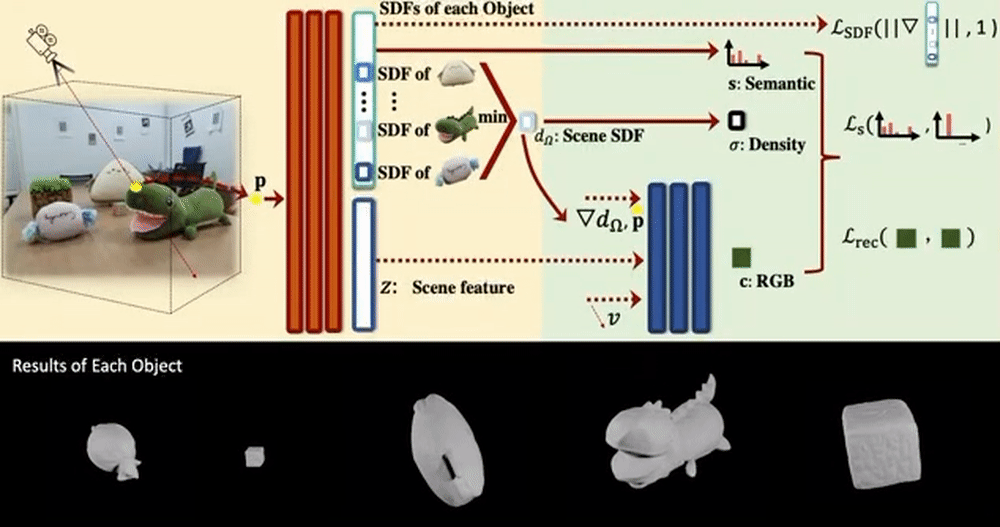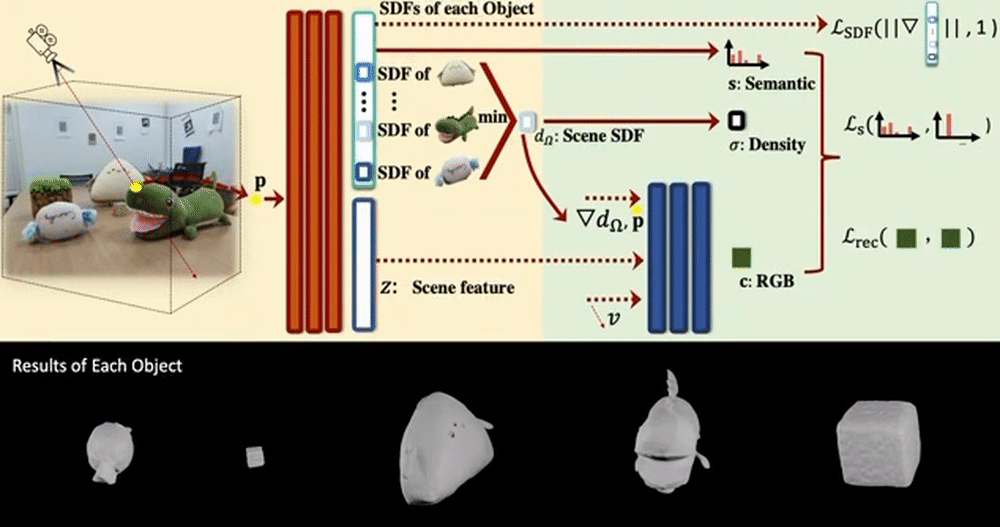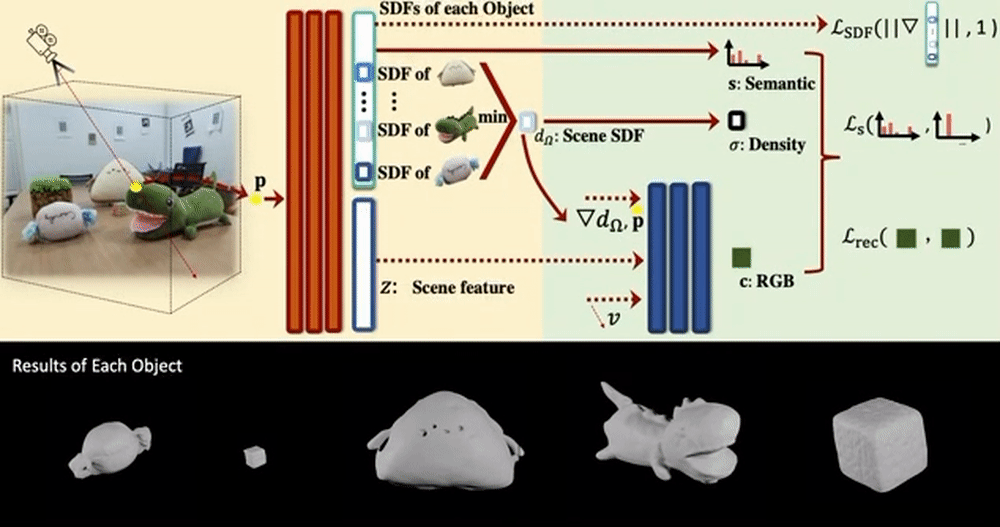
This section covers NeRFs that propose composing, controlling, or editing methods.
Deforming Radiance Fields with Cages uses low-poly cages around the object to create a simple deformation target. Deforming the cage is then simple with manual editing. The deformation can warp the previously trained NeRF with a dense warping field.
Object-Compositional Neural Implicit Surfaces models a scene as a combination of Signed Distance Functions (SDF) of individual objects. For this, the strong association between an object’s SDF and semantic label is used, and the semantics are tied to the SDF from each object.
Pose Estimation

Estimating the pose of objects or the camera is a fundamental problem in computer vision.
Neural Correspondence Field for Object Pose Estimation estimates the pose of an object with a known 3D model by constructing neural correspondence fields, which create a 3D mapping between query points and the object space.
RayTran estimates the pose of objects and the shape from RGB videos. Here, a global 3D grid of features and an array of view-specific 2D grids is used. A progressive exchange of information is performed with a bidirectional attention mechanism.
GARF proposes to leverage Gaussian activation functions for pose estimation. Similar to BARF, the method also increases the bandwidth of the Gaussian function over time.
Decomposition
PANDORA enables decompositions into shape, diffuse, and specular using polarization cues.
In this section, the radiance of NeRF is split into geometry, BRDF, and illumination. This enables consistent relighting under any illumination.
NeRF-OSR enables relighting of outdoor scenes by decomposing the radiance to an albedo, Spherical Harmonics (SH) illumination model and explicitly modeling the shadowing from the SH illumination.
PANDORA leverages polarization cues to accurately predict shapes and decompositions into diffuse and specular components.
Relightable dynamic humans are enabled with Relighting4D. Here, the human body is decomposed into surface normals, occlusion, diffuse, and specular with neural fields and rendered with a physically-based renderer.
PS-NeRF learns a decomposition from images under sparse views, where each view is illuminated by multiple unknown directional lights. The method can produce detailed surfaces from sparse viewpoints with a shadow-aware renderer and supervision from the multiple illumination images.
NeILF represents scene lighting as a neural incident light field, which handles occlusions and indirect illumination. With this illumination representation, a decomposition into BRDFs is performed, which a regularized with a Lambertian assumption and bilateral smoothness.
Other
ARF enables simple stylization of NeRF reconstructions.
Several works with excellent results in various fields.
RC-MVSNet introduces neural rendering to Multi-View Stereo (MVS) to reduce ambiguity in correspondences on non-Lambertian surfaces.
What if we do not reconstruct photorealistic 3D scenes but style them according to paintings? ARF creates these highly stylized novel views from regular radiance fields.
LTEW introduces continuous neural fields to image warping. The method enables learning high-frequency content with a Local Texture Estimator instead of the classical NeRF Fourier embedding.
Periodic patterns appear in many man-made scenes. NeRF-style methods do not capture these periodic patterns. NPP introduces a periodicity-aware warping module in front of the neural field.
Implicit Neural Representations for Image Compression investigates using neural fields for image compression tasks by introducing quantization, quantization-aware retraining, and entropy coding to neural fields. Meta-learned initializations from MAML also enable shorter training times.
Neural Strands focuses on hair representation based on a neural scalp texture that encodes the geometry and appearance of individual strands at each texel location. The rendering is performed based on rasterization of the learned hair strands.
DeepShadow learns a 3D reconstruction (depth and normals) based on shadowing. For this, the shadow map generated from a neural field that learns the depth map and a light position is compared to the actual captured one.
LaTeRF is a method for extracting an object from a neural field given a natural language description of the object and a set of point-labels of object and non-object points in the input images.
Towards Learning Neural Representations from Shadows estimates the shape from shadows using a neural shadow field. Here, a shadow mapping approach is used to render the shadows, which can be compared to the ground truth shadows.
Minimal Neural Atlas learns an explicit neural surface representation from a minimal atlas of 3 charts. With a distortion-minimal parameterization for surfaces, arbitrary topology can be represented.
Unified Implicit Neural Stylization enables stylized neural fields by learning the style of a painting and the content of the scene separately and combining them in an Amalgamation module.
Conclusion
This is my second time doing a conference roundup, and the number of papers is quite stunning. This time I gathered 50 papers from just a single conference. NeurIPS had 36. If we also take CVPR into account (57 papers), the 3 conferences alone this year produced over 140 NeRF-related papers.
There are several trends in this year’s ECCV. One major one is combining transformers with NeRFs and, in general, adding neural priors. This trend was also visible in my NeurIPS roundup. Another large one is examining NeRF and finding ways to express high-frequency data more easily or capture vast scenes. In my opinion, it is also amazing to see several works which decompose into BRDF, shape, and illumination or to see techniques such as shadow mapping being used in NeRFs.
