ReSWD Accepted at ECCV 2026
ReSWD got accepted to ECCV 2026. Check out the project page, code, and demo.
Mark Boss is the Co-Head of 3D & Image at Stability AI. He worked at Unity Technologies before and completed his PhD at the University of Tübingen in the computer graphics group of Prof. Hendrik Lensch. His research interests lie at the intersection of machine learning and computer graphics, focusing mainly on inferring physical properties (shape, material, illumination) from images.
If you are interested in a research collaboration, please drop me an email with your CV.
PhD in Computer Science
2023
University of Tübingen
MSc in Computer Science
2018
University of Tübingen
BSc in Computer Science
2016
Osnabrück University of Applied Sciences
ReSWD got accepted to ECCV 2026. Check out the project page, code, and demo.
Three new papers are now available on ArXiv:
ReLi3D got accepted to ICLR 2026. Check out the project page, code, and models.
Stable Virtual Camera and SViM3D got accepted to ICCV 2025.
ILR+G Workshop @ ICCV
Instance-level generation and editing and the application in profession media production. This talk discusses recent advances in this field.
AI4CC Workshop @ CVPR
Generative AI can unlock several tasks and subtasks in profession media production. This talk discusses recent advances in this field.
Games Day 2023
Asset production in the game industry is time-consuming, and since "The Vanishing of Ethan Carter" photogrammetry has gained traction. While the asset produced by photogrammetry achieves incredible detail, the illumination is baked into the texture maps. This makes the assets inflexible and limits their use in games and movies without manual post-processing. In this talk, I will present our recent work on decomposing an object into its shape, reflectance, and illumination. This highly ill-posed problem is inherently more challenging when the illumination is not a single light source under laboratory conditions but is an unconstrained environmental illumination. Decomposing an object under this ambiguous setup enables the automated creation of relightable 3D assets for AR/VR applications, enhanced shopping experiences, games, and movies from online images. In this talk, I will present our recent methods in the field of reflectance decomposition using Neural Fields. Our methods are capable of building a neural volumetric reflectance decomposition from unconstrained image collections. Contrary to most recent works that require images to be captured under the same illumination, our input images are taken under varying illuminations. This practical setup enables the decomposition of images gathered from online searches and the automated creation of relightable 3D assets. Our techniques handle complex geometries with non-Lambertian surfaces, and we also extract 3D meshes with material properties from the learned reflectance volumes enabling their use in existing graphics engines. In our last method, we also enable the decomposition of unposed image collections. Most recent reconstruction methods require posed collections. However, common pose recovery methods fail under highly varying illuminations or locations.
In this talk, I will present our recent work on decomposing an object into its shape, reflectance, and illumination. This highly ill-posed problem is inherently more challenging when the illumination is not a single light source under laboratory conditions but is an unconstrained environmental illumination. Decomposing an object under this ambiguous setup enables the automated creation of relightable 3D assets for AR/VR applications, enhanced shopping experiences, games, and movies from online images.In this talk, I will present our recent methods in the field of reflectance decomposition using Neural Fields. Our methods are capable of building a neural volumetric reflectance decomposition from unconstrained image collections. Contrary to most recent works that require images to be captured under the same illumination, our input images are taken under varying illuminations. This practical setup enables the decomposition of images gathered from online searches and the automated creation of relightable 3D assets. Our techniques handle complex geometries with non-Lambertian surfaces, and we also extract 3D meshes with material properties from the learned reflectance volumes enabling their use in existing graphics engines. In our last method, we also enable the decomposition of unposed image collections. Most recent reconstruction methods require posed collections. However, common pose recovery methods fail under highly varying illuminations or locations.
arXiv
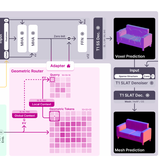
A trainable adapter for 3D generators that introduces explicit geometric control via typed constraint meshes (hull, avoidance, touch).
arXiv
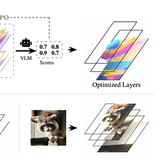
An RL framework that fine-tunes image layer decomposition models using VLM-as-judge rewards, eliminating paired supervision.
arXiv
A rotation-preconditioned KV cache codec that jointly quantizes coordinate triplets via an octahedral map, achieving state-of-the-art compression across text, video, and audio modalities.
ECCV 2026
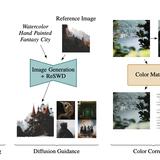
Distribution matching is central to many vision and graphics tasks, where the widely used Wasserstein distance is too costly to compute for high dimensional distributions. The Sliced Wasserstein Distance (SWD) offers a scalable alternative, yet its Monte Carlo estimator suffers from high variance, resulting in noisy gradients and slow convergence. We introduce Reservoir SWD (ReSWD), which integrates Weighted Reservoir Sampling into SWD to adaptively retain informative projection directions in optimization steps, resulting in stable gradients while remaining unbiased. Experiments on synthetic benchmarks and real-world tasks such as color correction and diffusion guidance show that ReSWD consistently outperforms standard SWD and other variance reduction baselines.
In ICCV
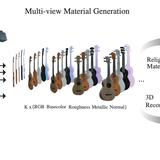
We present Stable Video Materials 3D (SViM3D), a framework to predict multi-view consistent physically based rendering (PBR) materials, given a single image. Recently, video diffusion models have been successfully used to reconstruct 3D objects from a single image efficiently. However, reflectance is still represented by simple material models or needs to be estimated in additional pipeline steps to enable relighting and controlled appearance edits. We extend a latent video diffusion model to output spatially-varying PBR parameters and surface normals jointly with each generated RGB view based on explicit camera control. This unique setup allows for direct relighting in a 2.5D setting, and for generating a 3D asset using our model as neural prior. We introduce various mechanisms to this pipeline that improve quality in this ill-posed setting. We show state-of-the-art relighting and novel view synthesis performance on multiple object-centric datasets. Our method generalizes to diverse image inputs, enabling the generation of relightable 3D assets useful in AR/VR, movies, games and other visual media.
In CVPR
Editing materials of objects in images based on exemplar images is an active area of research in computer vision and graphics. We propose MARBLE, a method for performing material blending and recomposing fine-grained material properties by finding material embeddings in CLIP-space and using that to control pre-trained text-to-image models. We improve exemplar-based material editing by finding a block in the denoising UNet responsible for material attribution. Given two material exemplar-images, we find directions in the CLIP-space for blending the materials. Further, we can achieve parametric control over fine-grained material attributes such as roughness, metallic, transparency, and glow using a shallow network to predict the direction for the desired material attribute change. We perform qualitative and quantitative analysis to demonstrate the efficacy of our proposed method. We also present the ability of our method to perform multiple edits in a single forward pass and applicability to painting.
Stability AI
Stability AI
Unity
University of Tübingen
NVIDIA
zahlz
University of Tübingen
University of Tübingen
Osnabrück University of Applied Sciences

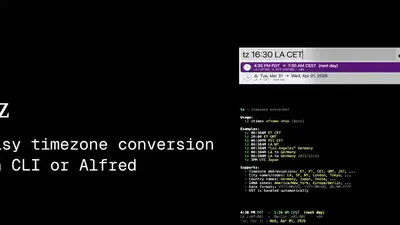
A fast timezone converter for the command line and Alfred. Supports timezone abbreviations, city names, country names, and automatic daylight saving time handling.
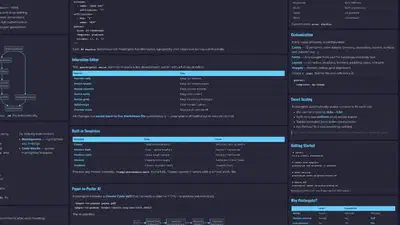
Academic poster generator that converts Markdown files to beautiful HTML posters with live preview, drag-and-drop editing, and PDF export. Also supports a Claude Code Skill to turn …
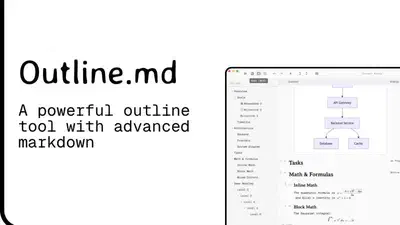
A cross-platform, markdown-based hierarchical outline editor built with Flutter. Create structured documents using familiar markdown headings, export to LaTeX, and organize your …
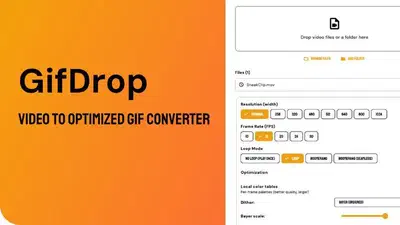
GifDrop is a desktop app that converts video to GIF and optimizes existing GIFs. Drag and drop your files, tweak quality and size, and export—no command line required. It bundles …
Checks, standardizes, and upgrades .bib files automatically.
It is now my third time writing a summary of NeRFy things at a conference. This time it is the big one: CVPR. The list of accepted papers is massive again, with 2359 papers.
I recently went through the the provisional programm of ECCV 2022. After my last post on “NeRF at NeurIPS” got such great feedback, and I anyway compiled a list of all NeRFy things, I decided to do it all again.
Inspired by Frank Dellaert and his excellent series on the original NeRF Explosion and the following ICCV/CVPR conference gatherings, I decided to look into creating a NeurIPS 22 rundown myself.
The papers below are all the papers I could gather by browsing through the extensive list of accepted NeurIPS papers. I mainly collected all papers where the titles fit and did a brief scan through the paper or only the abstract if the paper wasn’t published at the time of writing. If I have mischaracterized or missed any paper, please send me a DM on Twitter @markb_boss or via mail.